Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover Big Tech and startups through the lens of senior engineers and engineering leaders. Today, we cover one out of four topics from this past The Pulse issue. Full subscribers received the article below two weeks ago. If you’ve been forwarded this email, you can subscribe here.
On the evening of Thursday, 7 May, trading at Coinbase went offline and stayed that way for nearly 10 hours (!!). Customers could not buy, sell, deposit, receive, or withdraw. Basically, the core services of Coinbase were unavailable.
The outage coincided with a regional AWS outage. But no other company suffered a global outage; the most I observed was a few infra companies like Datadog noting that some regions had issues, and were failing over to a healthy region.
It’s weird that Coinbase – a $40B company! – told customers to monitor AWS’s status pages for recovery. This made it pretty clear that the company fully depends on a single AWS zone. Unusually, Coinbase deleted this information from its status page, but I got a screenshot first:
{kind=link}
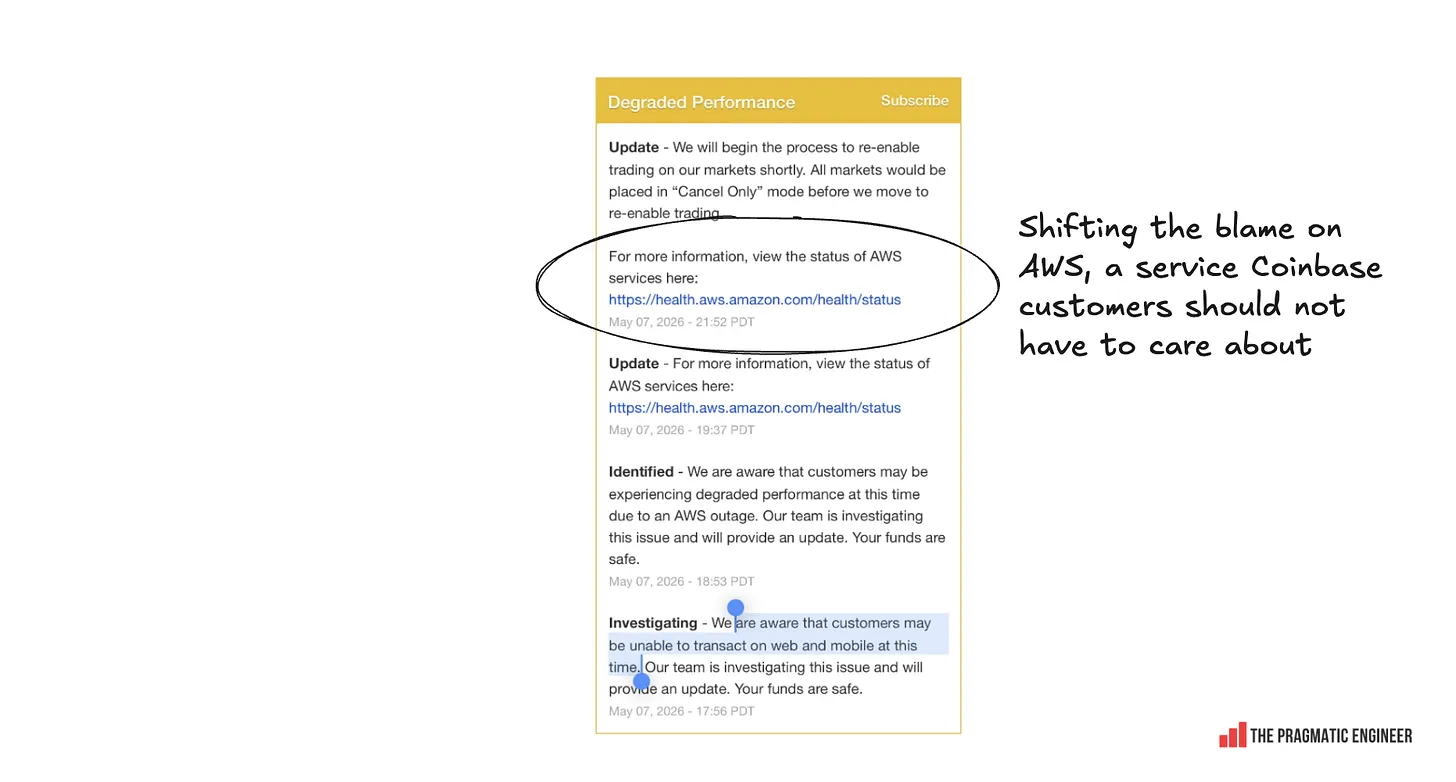
Coinbase later confirmed that it does indeed have a single-availability zone dependency. From its postmortem:
“Our matching engine was pinned to a single building. The Coinbase Exchange matching engine runs as a Raft-based replicated cluster inside an AWS Cluster Placement Group. We make this choice deliberately. A matching engine that meets the latency and throughput demands of a serious market cannot tolerate inter-zone network hops between voting cluster members. The physics of distributed consensus and the economics of running a fair, liquid order book point to the same answer, which is co-location.”
A quick recap on the difference between an availability zone (AZ) and region:
- Availability zone: One or more data centers (in the case of AWS, it is usually several data centers) located close enough to have low latency between them. Data centers in different AZs must be independently resilient. In the same AZ, there is no such requirement.
- Region: Within AWS, this consists of at least three isolated, physically separated AZs, usually 10-30 miles apart. It’s unlikely they’ll go down simultaneously, even in extreme circumstances.
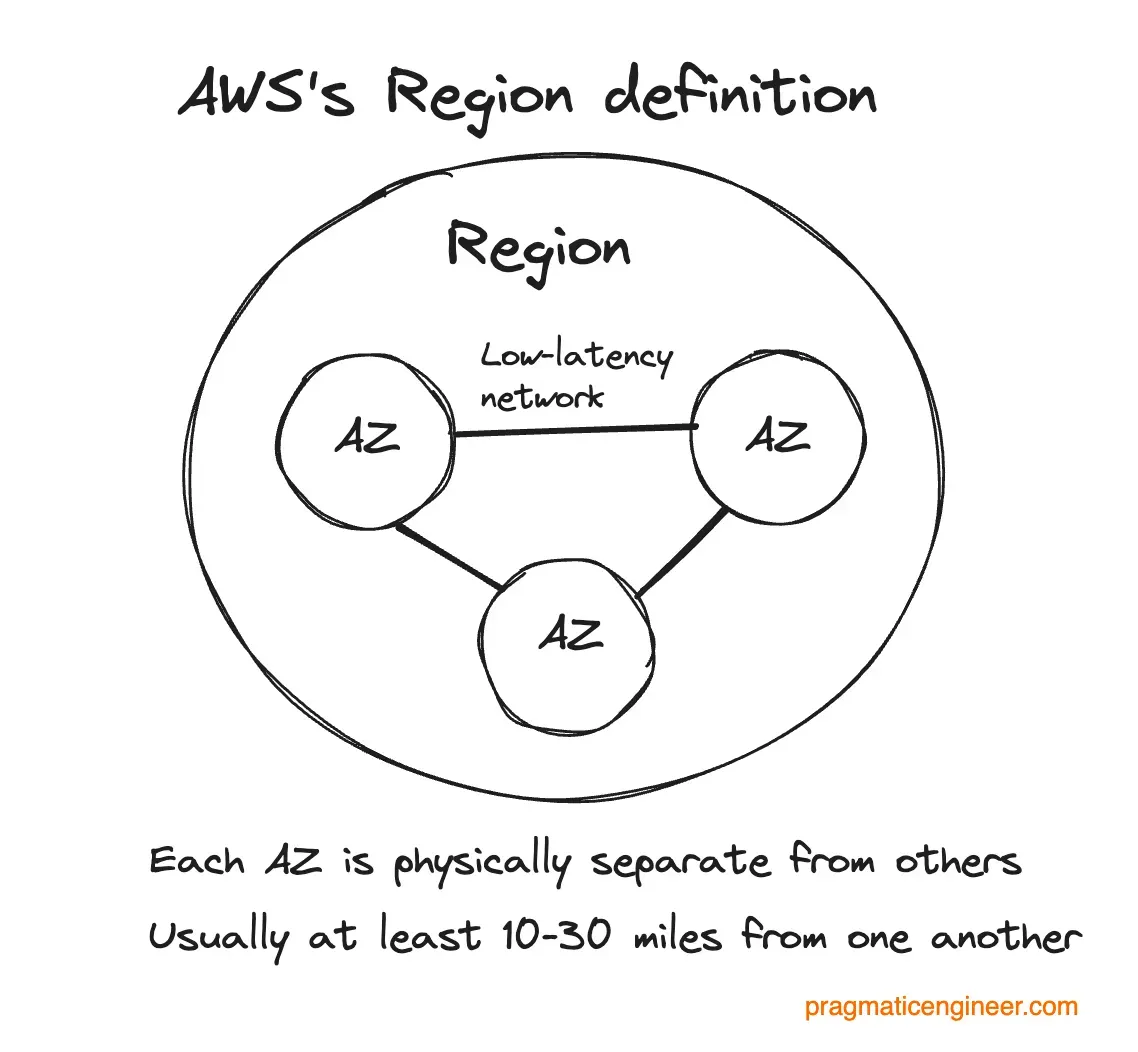
Coinbase is saying that running from more than one availability zone (AZ) (building) would introduce too much latency to their product. This makes sense for low-latency activities like trading. But what about preparing for a failover as and when the AZ goes down? After all, an AZ is not guaranteed to have high uptime!
Turns out, Coinbase did not prepare for a failover for an AZ. Also from its postmortem (emphasis mine):
“We lacked an automated ability to fail over to another availability zone. When AWS terminated EC2 instances inside our placement group at 9:29 PM ET, three of five matching-engine nodes went down and we lost quorum. There was no automated cross-zone failover. Recovery required an emergency code change shipped during the incident to remove a startup assumption that all five cluster nodes were resolvable, the creation of a new node group outside the impaired placement group, and a careful sequence to restore a 3-of-5 quorum. This allowed us to reopen markets: first cancel-only, then auction mode, and finally full trading.”
Having no automated failovers is incredibly amateurish for an operation of Coinbase’s scale. Coinbase moves about 5.2 trillion dollars per year, and is valued at around $40B. The outage interrupted around $7 billion-worth of financial activity, based on my napkin math.
Back in 2016, Uber was valued at roughly as much as Coinbase, and handled circa $40-50B yearly. It had two data centers on the east and west coasts, and operated more as if it ran out of two zones. I worked at Uber at the time and there were regular failover drills to another data center (another region), in preparation should a region go down. Uber’s business, in terms of the financial figures, was a fraction of Coinbase’s!
My impression of Coinbase’s engineering culture has sunk after this incident, and it’s almost comical that CEO Brian Armstrong is boasting that non-technical teams now ship production code, thanks to AI. This feels like the wrong thing to focus on when Coinbase’s infrastructure basics seem to be in far worse shape in 2026 than Uber’s were a decade ago in 2016!
It seems Coinbase did not learn lessons after getting burned by previous regional AWS outages. In October 2025, the company suffered a three-hour-long global trading outage due to issues with AWS’s DynamoDB service. Following that outage, Coinbase engineering said (emphasis mine):
“To be better prepared in the future, we are exploring all options, including reviewing our regional deployment strategy to implement immediate and long-term fixes to reduce the impact of these types of outages.”
That process of reviewing the regional deployment strategy evidently missed or ignored the risk of a single-zone dependency of the heart of the business, with no cross-zone failover.
Read the full The Pulse issue.
Subscribe to my weekly newsletter to get articles like this in your inbox. It's a pretty good read - and the #1 software engineering newsletter on Substack.