Do you actually use data structures and algorithms on your day to day job? I've noticed a growing trend of people assuming algorithms are pointless questions that are asked by tech companies purely as an arbitrary measure. I hear more people complain about how all of this is a purely academic exercise. This notion was definitely popularized after Max Howell, the author of Homebrew, posted his Google interview experience:
Google: 90% of our engineers use the software you wrote (Homebrew), but you can’t invert a binary tree on a whiteboard so fuck off.
— Max Howell (@mxcl) June 10, 2015
While I've also never needed to use binary tree inversion, but I have come across everyday use cases of data structures and algorithms when working at Skype/Microsoft, Skyscanner and Uber. This included writing code and making decisions based on these concepts. But for the most part, I used this knowledge to understand how and why some things were built. Knowing these concepts made it easy to understand design and implementations referencing these.
This article is a set of real-world examples where data structures like trees, graphs, and various algorithms were used in production. I hope to illustrate that a generic data structures and algorithms knowledge is not "just for the interview" - but something that you'd likely find yourself reaching for when working at fast-growing, innovative tech companies. If you want to buy one book that teaches you everything you need to know for the majority of interviews, Grokking Algorithms is hands down the best guide.
Note that none of the below links are affiliate links or sponsored. See my ethics statement on the lack of such links.
I've used a very small subset of algorithms, but almost all data structures. It should be of no surprise that I am no fan of algorithm-heavy and non-practical interview questions with exotic data types like Red-Black trees or AVL trees. Never asked these, and never will. You can read about what I think about these interviews at the end of this article. Still, there is lots of value in being aware of what options for basic data types they can choose to tackle certain problems. With this, let's jump into examples.
Trees and tree traversing: Skype, Uber and UI frameworks
When we built Skype of Xbox One, we worked on a barebones Xbox OS, that was missing key libraries. We were building one of the first full-fledged applications on the platform. We needed a navigation solution that we could hook up both to touch gestures and to voice commands.
We built a generic navigation framework on top of WinJS. To do so, we needed to maintain a DOM-like graph to keep track of the actionable elements. To find these elements, we did DOM traversal - basically, a tree traversal - across the existing DOM. This is a classic case of BFS or DFS (breadth-first search or depth-first search).
If you're doing web development, you already work with a tree structure: the DOM. All DOM nodes can have children and the browser renders nodes on-screen after traversing the DOM tree. If you are searching for a specific element, you can use built-in DOM methods to find it - such as getElementById - or you could implement a BFS or DFS search to go through all the nodes, similar to how it's done in this example.
Many frameworks that render UI elements use tree structures behind the scenes. React maintains a virtual DOM, and uses smart reconciliation - a "diffing" algorithm - to deliver great performance, by only re-rendering parts of the screen that's changed. Ryan Bas visualizes this process in his writeup on React reconciliation.
Uber's mobile architecture, RIBs uses trees as well - similar to most UI frameworks that render elements in a hierarchy. RIBs maintains a RIB tree for state management, attaching and detaching the RIBs that need to be rendered. When working with RIBs, we would sometimes sketch where the new RIBs would fit in the hierarchy, and discuss whether the RIBs in question should have views - making it a part of the view hierarchy - or just manage state.
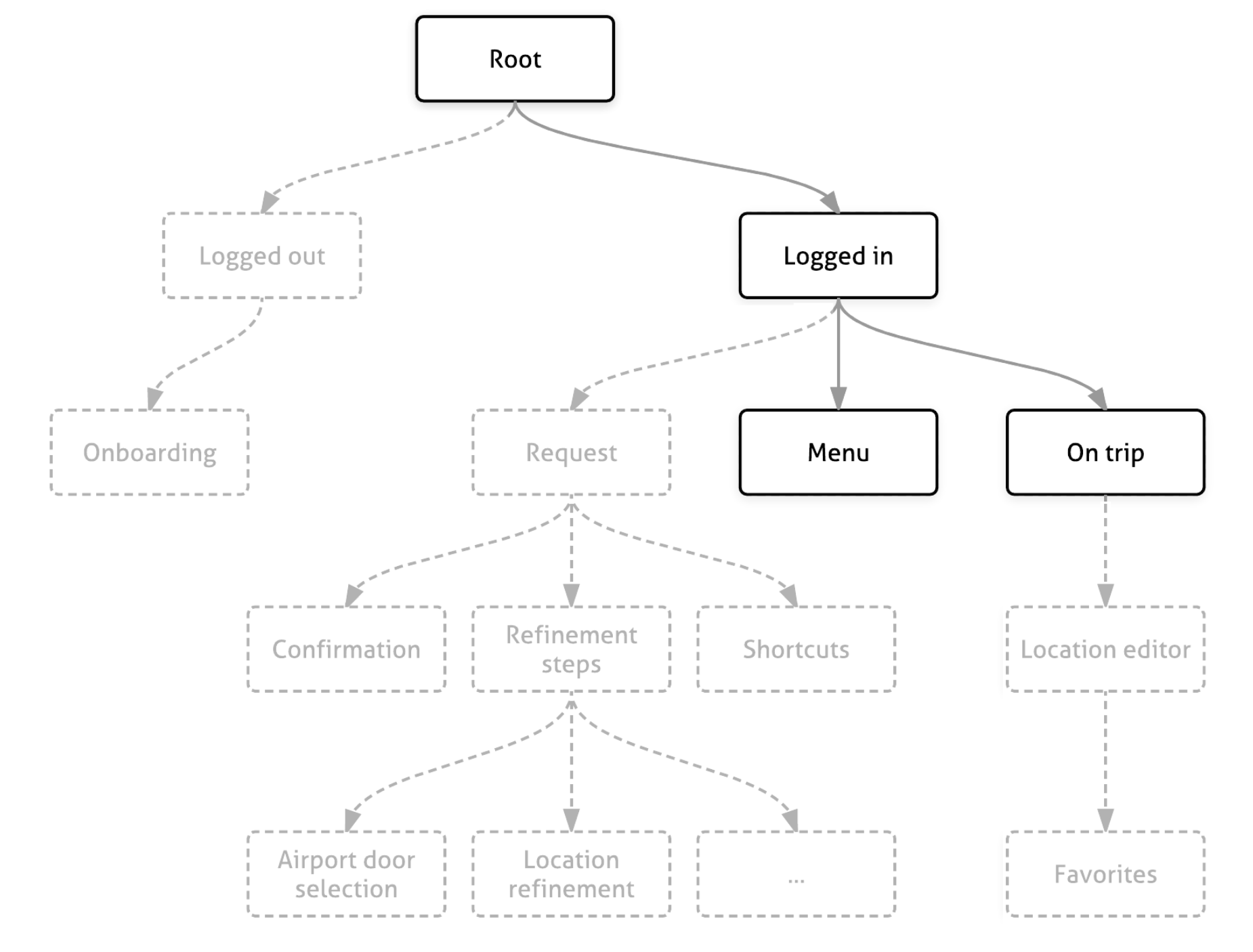
If you ever find yourself needing to build visualization of hirearchical elements, a common approach is to use a tree-like structure, traverse the tree and render the elements you visit. I've come across many internal tools that use this approach. An example is the RIBs visualization tool built by Uber's Mobile Platform team, that you can see in a demo in this video.
Weighed graphs and shortest paths: Skyscanner
Skyscanner finds the best deals on airline tickets. It does this by scanning all routes worldwide, then putting them together. While the nature of the problem is more on crawling, and less on caching - as airlines calculate the layover options - the multi-city planning option becomes the shortest path problem.
Multi-city was one of the features that took Skyscanner quite a bit of time to build - in all fairness, the difficulty was more on the product side, than anything. The best multi-city deals are calculated by using shortest path algorithms like Dijkstra or A*. Flight routes are represented as a directed graph, with each edge having a weight of the cost of the ticket. Calculating the cheapest price option between two cities was done via an implementation of a modified A* search algorithm per route. If you're interested in flights and shortest paths, the article on implementing the shortest flight search path using BFS by Sachin Malhotra is a good read.
With Skyscanner, the actual algorithm was far less important, though. Caching, crawling, and handling the varying website load were much more difficult things to crack. Still, a variation of the shortest paths problem comes up with many several travel companies that optimize for price based on combinations. Unsurprisingly, this topic was also a source of hallway discussions here.
Sorting: Skype (kind of)
Sorting is an algorithm family I rarely had an excuse to implement or needed to use in-depth. It's interesting to understand the different types of ways to sort, from bubble sort, insertion sort, merge sort, selection sort and - the most complex one - quicksort. Still, I found that there is rarely a reason to implement any of this, especially when you don't need to write sort functions as part of a library.
At Skype, I got to exercise a bit on this knowledge, though. One of the other engineers decided to implement an insertion sort for listing contacts. In 2013, when Skype connected to the network, contacts would arrive in bursts, and it would take some time for all the contacts to arrive. So this engineer thought it's more performant to build the contact list organized by name, using insertion sort. We had a back-and-forth on this, over why not just use the default sort algorithm. In the end, it was more work to properly test the implementation, and to benchmark it. I personally didn't see much point in doing so: but we were in the stage of the project that we had the time.
There are definitely some real-world use cases where efficient sorting matters, and having control over what type of sorting you use, based on the data, can make a difference. Insertion sort can be useful when streaming realtime data in large chunks and building realtime visualization for these data sources. Merge sort can work well with divide-and-conquer approaches if it comes to large amounts of data stored on different nodes. I've not worked with these, so I'll still mark sorting algorithms as something with little day-to-day use, beyond the appreciation of the different approaches.
Hashtables and hashing: everywhere
The most frequent data structure I've used regularly was hashtables and the hashing function. It's such a handy tool from counting, to detecting duplications, to caching, all the way to distributed systems use cases like sharding. After arrays, it's easily the most common data structure I've used on countless occasions. Almost all languages come with this data structure, and it's simple to implement if you'd need it.
Stacks and queues: every now and then
The stack data structure will be very familiar to anyone who has debugged a language that has a stack trace. As a data structure, I've had a few problems to use it for, but debugging and performance profiling makes me intricately familiar with it. It's also an obvious choice when traversing a tree depth-first.
I rarely had to choose queues as data structures for my code, but I came across it plenty of times in codebases, code popping, or pushing values in it. A common use case is implementing BFS traversing of trees, where the queue data structure lends itself. You can also use queues for a variety of other use cases. I once read code scheduling jobs that made good use of priority queues, running the shortest jobs first, using the Python heap queue algorithm.
Crypto: Uber
User-entered sensitive information coming from mobile or web clients needs to be encrypted before sending through the network, only to be decrypted on a specific service. To do so, a crypto approach needs to be implemented on the client and the backend.
Understanding crypto is interesting. You don't come up with a new algorithm - this can be one of the worst ideas to do. Instead, you take an existing, well-documented standard and the use the framework built-in primitives. The standard of choice is usually a part of the AES standard. If it's secure enough to encrypt classified US information, and there is no known, working attack on the protocol, AES192 or AES256 is usually a secure enough choice for most use cases.
When I joined Uber, mobile and web crypto were already implemented on top of these primitives, giving me the excuse to look up details of the Advanced Encryption Standard (AES), Hashed Message Authentication Codes (HMAC), the RSA public-key encryption and others. Understanding how a series of encryption steps are provably secure was another interesting area. Between encrypt-and-MAC, MAC-then-encrypt, and encrypt-then-MAC, only one of them is provably secure - even though this doesn't mean the others are not secure.
Implementing crypto primitives is rarely ever something you will ever need to do - unless building a brand new core framework. However, deciding on which primitives to use, how to combine primitives is a decision you might face - or have to understand why a certain approach was taken.
Decision trees: Uber
On one of the projects, we had to implement complex business logic in the mobile application. Based on half a dozen rules, we had to display one of several different screens. The rules were unusually complex due to a series of compliance checks and user choices that we needed to take into account.
The engineer building this feature first tried to code the rules with a series of if-else statements, which got too complex. In the end, they decided to go with a decision tree, as it was easy to validate with product and compliance, reasonable to implement and easy to change, if needed. We needed to build an implementation for edges to execute rules, but this was about it. While we could have saved implementing this tree with a different approach, the team found this solution to be easier to maintain, going forward. Here's how the decision tree looked like - the edges being results of rules executed (either binary outcome or value ranges) and the leaf nodes marking what screen to transition to.
Uber's mobile build system, called SubmitQueue, also utilizes decision trees built on the fly. The Developer Experience team had to solve the difficult problem of hundreds of mobile merges happening each day, with each build needing around 30 minutes to run - compiling, the running unit, integration, and UI tests. Parallelizing the builds was not a good enough solution, as two builds would often have overlapping changes, and a merge conflict would occur. In practice, this meant sometimes engineers would have to wait 2-3 hours, rebasing and staring the merge process again, and hoping there would be no conflict.
The Developer Experience team took an innovative approach by predicting merge conflicts and queued builds accordingly, using speculation graphs. Speculation graphs are very similar to binary decision trees:
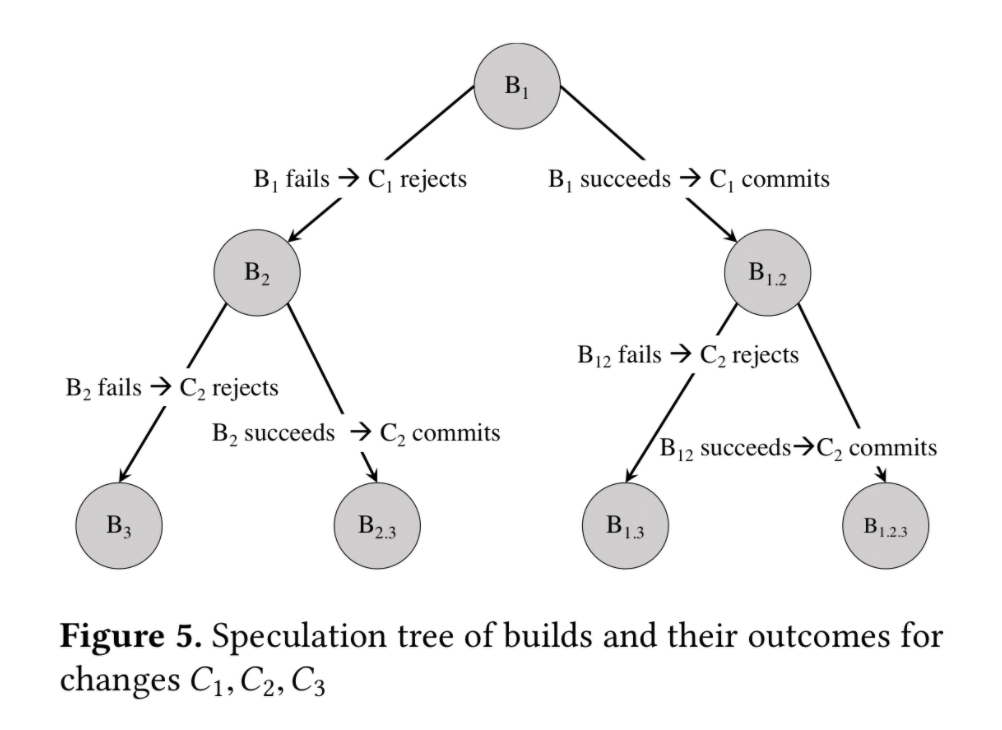
There are a lot more details in this whitepaper written by engineers on the Developer Experience team who built the solution - and this paper is a great read. Adrian Colyer also has a nice, visual analysis on the approach. The result was a much faster build system that optimized build time, and made the lives of hundreds of mobile engineers far more pleasant.
Hexagonal Grids, Hierarchical Indexes: Uber
This last project is one I've come about purely based on stumbling across it. I learned about a new data structure: hexagonal grids with hierarchical indexes.
One of the most difficult and interesting problems to solve at Uber is how to optimize the pricing of trips, and the dispatching of partners. Prices can be dynamic, and drivers are constantly on the move. H3 is a grid system engineers built to both visualize and analyze data across cities, at an increasingly granular level. The data - and visualization - structure for this is a hexagonal grid with hierarchical indexes, and a couple of internal visualization tools are built on top of it.
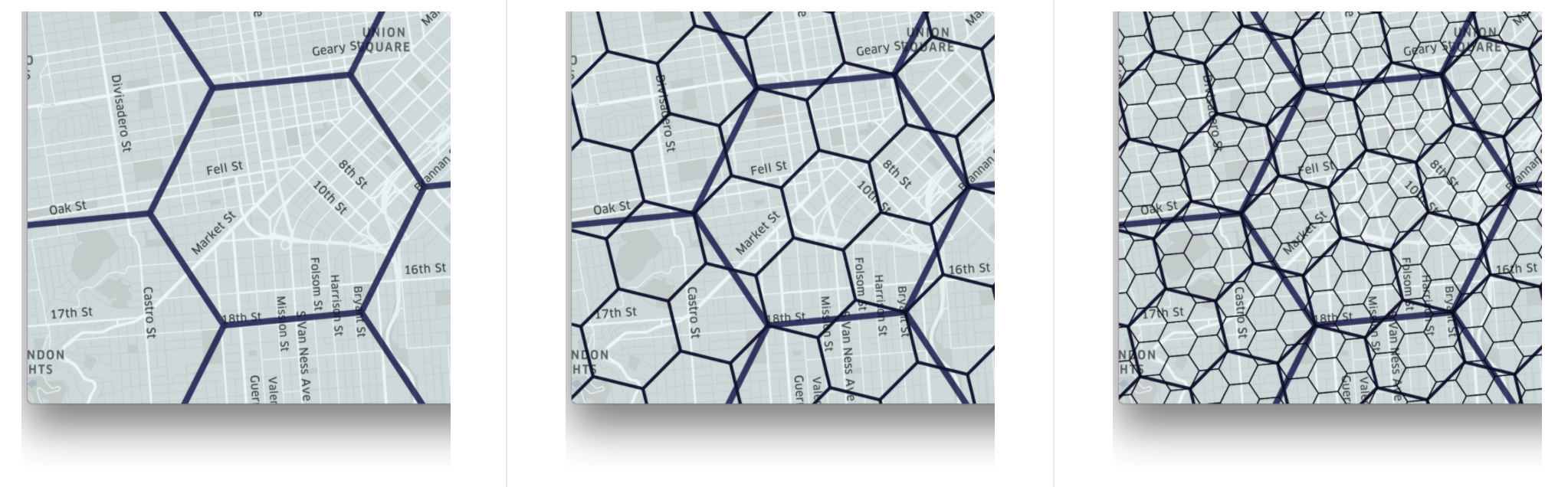
The data structure has specific indexing, traversal, hierarchical grid, region, and unidirectional edge functions, detailed in the API reference. For a more detailed deep-dive, see the article on the H3 library, the source code, or the presentation on how and why this tool was built.
What I really liked about this experience is learning that creating your own specialized data structures can make sense in a niche area. There aren't many use cases where hexagonal grids with hierarchical indexes would make sense beyond combining mapping with various data levels within each cell. Still, if you're familiar with some data structures, understanding this new data structure is much easier - as it would be for you to design yet another data structure for a similarly specialized need.
Interviews and algorithms and data structures
Those were the highlights of the actual data structures and algorithms I've come across professionally between multiple companies and many years. So let's go back to the original tweet that complained about asking things like inverting a binary tree on a whiteboard. I'm on Max's side on this one.
Knowing how complex algorithms or exotic data structures work are not something you should need to know to work at a tech company. You should know what an algorithm is, and should be able to come up with simple ones on your own, like a greedy one, a breadth-first or depth-first search or a simpler sorting algorithm. You should also know about basic data structures that are pretty common, like hashtables, queues, or stacks. But more complicated algorithms like Quicksort, Dijkstra, A* and more advanced ones are not things you'd need to memorize: you'll have a reference for this. The most I did with algorithms beyond sorting was look them up and understand them myself. Same with exotic data structures like Red-Black trees or AVL trees. I've never had to use these data structures. Even if I did, I would look them up again. I have never asked questions that needed this kind of knowledge to solve them, and never will.
I am all for asking practical coding exercises, where there are many good solutions, from brute force or greedy approaches to potentially more sophisticated ones. For example, asking to implement a justify text function like this question is a fair one: it's something I did when building a text rendering component on Windows Phone. You can solve this problem just by using an array and a few if/else statements, without any fancy data structures.
The reality is that many teams and companies are going overboard with algorithmic challenges. I can see the appeal of algorithmic questions: they give you signal in 45 minutes or less, and questions can be easily swapped around; thus, there is little harm if the question leaks. They are also easy to scale when recruiting, as you can have a question pool of 100+ questions, and any interviewer can evaluate any of them. Especially in Silicon Valley, it is more and more common to hear questions geared for dynamic programming or exotic data structures. These questions will help hire strong engineers - but also result in turning away people who would have excelled at a job that doesn't need advanced algorithms knowledge.
To anyone reading whose company has a bar to hire people who know some of the advanced algorithms by heart: think again if this is what you need. I've hired fantastic teams at Skyscanner London and Uber Amsterdam without any tricky algorithm questions, covering no more than data structures and problem solving. You shouldn't need to know algorithms by heart. What you do need is awareness of the most common data structures and the ability to come up with simple algorithms to solve the problem at hand, as a toolset.
Data structures and algorithms are a toolset
If you work in a fast-moving, innovative tech company, you will almost certainly come across all sorts of data structures and different algorithm implementations in the codebase. When you build new and innovative solutions, you will often find yourself reaching to the right data structure. This is when you'll want to be aware of the options to choose from and their tradeoffs.
Data structures and algorithms are a tool that you should use with confidence when building software. Know these tools, and you'll be familiar with navigating codebases that use them. You'll also be far more confident in how to implement solutions to hard problems. You'll know the theoretical limits, the optimizations you can make, and you'll come up with solutions that are as good as they get - all tradeoffs considered.
To get started, I recommend the following resources:
- Read up on the hashtable, linked list, tree, graphs, heap, queue, and stack data structures. Play around with how to can use them in your language. GeeksforGeeks has a good overview on these. For coding practice, I'd recommend the HackerRank Data Structures collection.
- Grokking Algorithms by Aditya Bhargava is hands down the best guide on algorithms from beginners to experienced engineers. A very approachable, and visual guide, covering all that most people need to know on this topic. I am convinced that you don't need to know more about algorithms than this book covers.
- The Algorithm Design Manual and Algorithms: Fourth Edition are both books I picked up back in the day to refresh some of the my university algorithm class studies. I gave up midway, and found them pretty dry, and not applicable to my day-to-day work.
Subscribe to my weekly newsletter to get articles like this in your inbox. It's a pretty good read - and the #1 software engineering newsletter on Substack.