Inside Agoda’s Private Cloud - Exclusive
👋 Hi, this is Gergely with the monthly, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at Big Tech and startups through the lens of engineering managers and senior engineers.
If you’re not a subscriber, you missed the issue on Shopify’s leveling split and a few others. Subscribe to get two full issues every week. Many subscribers expense this newsletter to their learning and development budget. If you have such a budget, here’s an email you could send to your manager. To get articles like this every week, subscribe here.
In a previous two-part series, we dived into Uber’s multi-year project to move onto the cloud, away from operating its own data centers. But there’s no “one size fits all” strategy when it comes to deciding the right balance between utilizing the cloud and operating your infrastructure on-premises.
To show the complexity of this choice and the ways tech businesses approach it, this article brings the inside story of one large tech company that’s decided against onboarding to the cloud – at least for now.
Agoda is a leading online travel booking platform in Asia. It’s owned by Booking Holdings Inc, which also owns the popular travel sites, Kayak and Booking.com. Unlike Uber, Agoda does not make use of public cloud providers, having decided to build out its own private cloud, instead.
To learn more, I reached out to Agoda’s CTO Idan Zalzberg who generously talked through previously not shared details.
In today’s issue, we cover:
- Agoda in numbers. The number of developers, physical cores, data centers, and more.
- The hardware inside Agoda’s private cloud. 64-core compute nodes of around 20 servers per rack, Top-of-rack (ToR) switches and plenty of redundancy.
- Agoda’s cloud strategy and usage. Is Agoda’s goal to operate off the cloud, or on it? What are the use cases where the company already utilizes public cloud?
- The cloud or your own data centers? Idan’s advice for any midsize company weighing up on-prem versus public cloud.
1. Agoda in numbers
Agoda lists 3.6M hotels and holiday properties worldwide, and its apps and website appear in 39 languages. The company sees 80K searches per second at peak traffic, and serving them all involves calculating 10M different “accomodation rates” per second. Interestingly, the majority of these searches are not by holidaymakers “browsing right now” during their free time – most searches are by partners, affiliates and search engines!
The company employs about 6,600 people in 31 markets, with its headquarters in Singapore. Around 1,600 people work in engineering, including software engineers, data science and business intelligence (BI) teams, and the DevOps team. The majority of the engineering team is in Bangkok, Thailand.
Among the 1,600 tech workers, the hardware team numbers in the low tens, and their job is to maintain the hardware and ensure it operates in DCs as expected. This group doesn’t include the software layer for infrastructure, which is a software team that builds the orchestration platform (Fleet) upon Kubernetes.
Although the company employs about 4-500 people in its data organization, there’s been no single dedicated “data team” for around 2 years. Agoda moved away from this model and its data engineers are embedded into each team. Within the data org, the distinct roles of data scientist, data analyst and data engineer are defined. Within data engineering, there is currently no separation between data engineers and machine learning (ML) engineers; individuals take on both roles. We go deeper into ML in What is ML engineering?
The company works in Scrum teams, which typically contain a product manager, developers, data scientists/analysts/engineers and BI engineers. The goal of having all these people is to create a shared business purpose.
Infrastructure-wise, the company operates around 6,500 servers, with a total of approximately 600k virtual cores (vCores) and 300k physical cores. The company’s largest data cluster is 20-30PB (petabytes: 1PB is 1,000 terabytes or 1M gigabytes). Ten years ago, this data cluster was 300GB as a Hadoop cluster; that’s around a 100,000-fold increase in data stored!
The company runs 4 data centers: in the US and Europe, with two in Asia. Agoda co-locates in all data centers, leasing space for its racks and the largest data center consumes about 1 MW of power. It uses Spark for the data platform. For transactional databases, it’s mostly the Microsoft SQL Server, but also other databases like PostgreSQL, ScyllaDB and Couchbase. At peak load, Agoda sees around 7.5M queries per second as total load, spread across its managed database-as-a-service (DBAAS.) The company uses HP servers, VAST hardware for object storage. Agoda utilizes Akamai as its CDN vendor.
2. The hardware inside Agoda’s private cloud
Agoda is standardizing its hardware SKUs (stock-keeping unit,) This is a unique code for a hardware that captures all the important details. The company standardizes SKUs to allow for supply chain optimization and ease of deployment. Typical compute nodes have:
- 64 cores physical cores, with SMT enabled (128 vCores)
- 512 GB memory
- 4 TB of storage
The company aims to maintain a similar ratio of cores / RAM / disk on all servers it buys. Here’s a common configuration:
- HPE ProLiant DL325 Gen10 Plus v2 Server
- CPU: 1x AMD 7763 CPU (64 physical cores)
- Memory: 512 GB of RAM
- Storage and 4 TB of NVMe (nonvolatile memory express) storage. NVMe is next-generation SSD

Agoda’s racks usually support 6-10 KW of load each, depending on the age of the facility. Often, around a dozen servers are deployed on a 6KW rack, equating to circa 1.5K vCores which can deploy approximately 20 servers with a 10KW rack, or around 2.5K vCores.
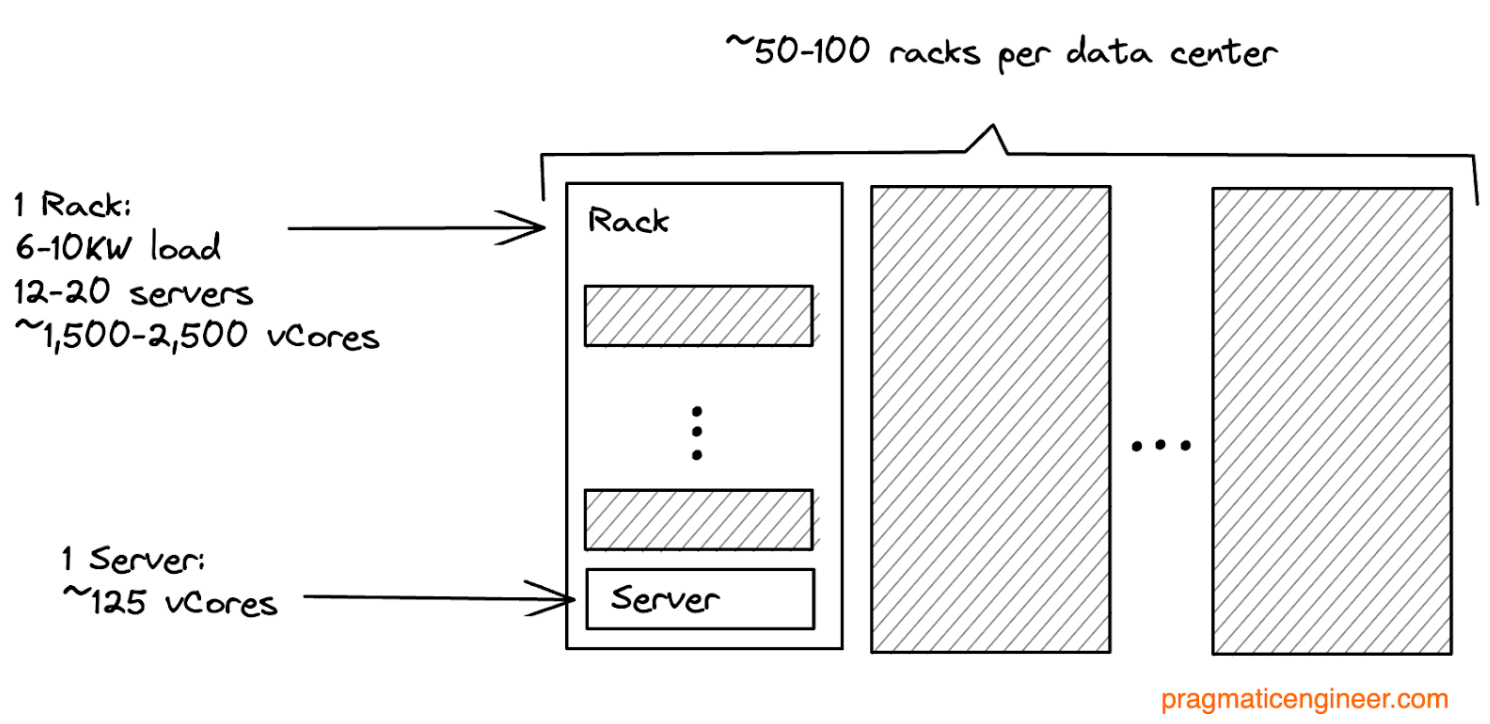
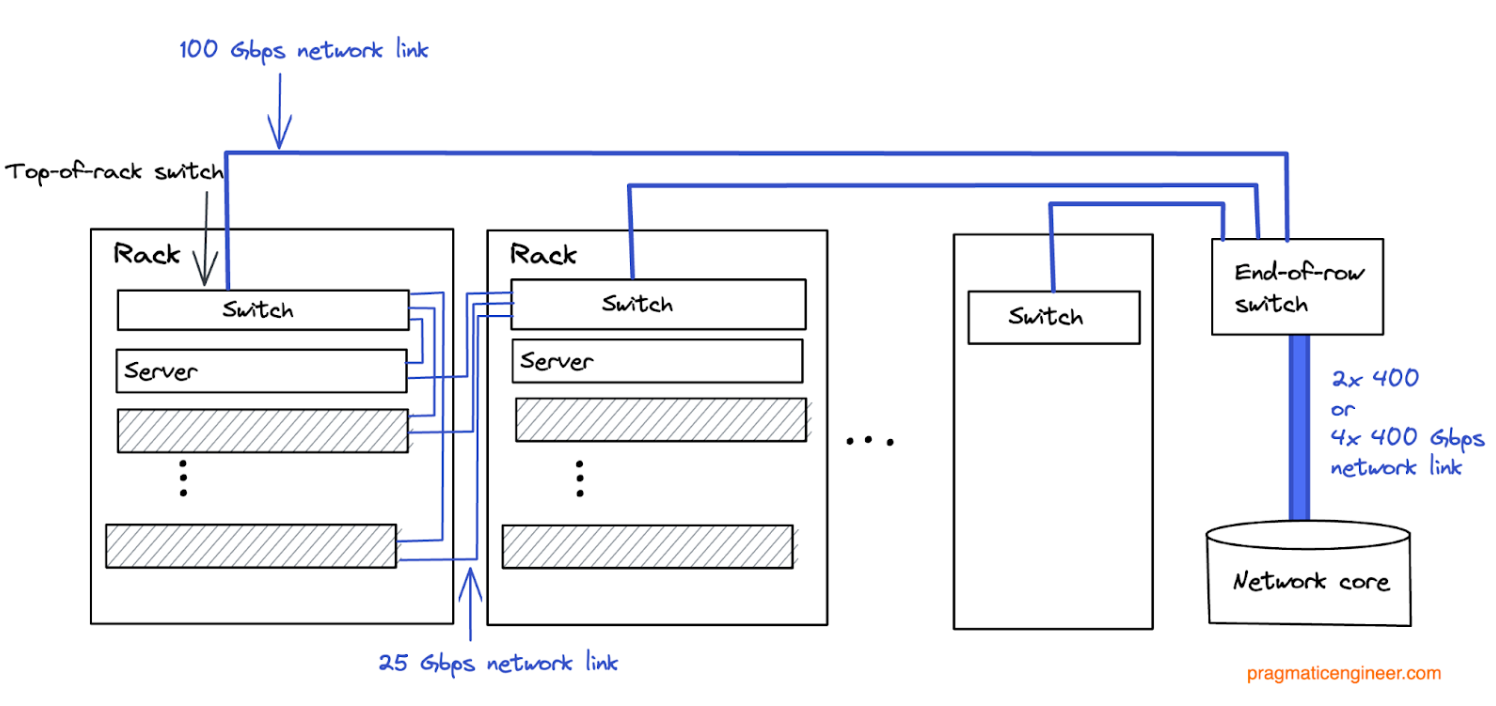
The company needs to plan server locations carefully in order to avoid hot spots and airflow problems. Each server has 2x25Gbps networking interfaces connected to dual switches of one switch per rack, and the cables cross between a rack pair.
Top-of-rack (ToR) switches connect to end-of-row switches with multiple 100 Gbps links, which connect to the network core with 2x400 or 4x400 Gbps links, depending on row size. Oversubscription, depending on rack density, is between 1.3:1 and 2:1.
Oversubscription in networking terms refers to having less network bandwidth available than the total capacity the network can theoretically handle. For example, assume a rack with 20 servers, each with a 25 Gbps card. To carry all the network capacity of these servers, you need 500 Gbps of bandwidth. However, if the top-of-the-rack switch has only 4x100Gbps of bandwidth, then oversubscription is 1.25:1 (500Gbps theoretical peak, vs 400 Gbps actual.)
Similarly, if you have 10 racks with 400 Gbps bandwidth per rack, you need 4,000 Gbps bandwidth at the end-of-rack switches. However, assuming 4x400Gbps switches, the oversubscription is 2.5:1 (4,000:1,600).
Oversubscription is a pragmatic approach to network planning, when considering cost control. Servers rarely use their maximum allocated bandwidth for prolonged periods, and it’s even less likely that this happens simultaneously to all servers in a rack, or for all racks in a row. In the case of Agoda, oversubscription was done after understanding the traffic patterns, and this setup does not interfere with being able to handle peak traffic loads.

The company uses Arista equipment in the DC. Due to supply chain issues, hardware refresh work is a bit behind, so a decent chunk of the racks are still on 10Gps ports. All of those ports are expected to be upgraded by 2024.
Needless to say, Agoda’s infrastructure is redundant. The company has two of pretty much everything, and redundant networking. They achieve inter-DC connectivity through a combination of:
- Point-to-point circuits
- MPLS circuits (muti-protocol label switching circuits)
- IPSec circuits (IP Security circuits)
Bandwidth between the main DCs is 40 Gbps, growing to 60 Gbps in the near future. It has optimized traffic paths for latency and route critical applications through the best circuits.
To reduce latency, a CDN is used. From a customer perspective, Agoda utilizes a CDN with a large local presence in core geographies, Akamai. The CDN manages caching and path optimization from the customer to Agoda, mitigating some common local access problems of remote locations. It also utilizes this distributed platform for security purposes, enriching data sent to the on-prem fraud detection platform.
For its data platform, Agoda builds on top of Spark. For the underlying hardware, it uses dual-socket HP Dl385 servers, with:
- 2x64-core AMD EPYC 7713 CPUs
- 2 TB of RAM
- 15 TB of NVMe, for caching purposes.

These HP servers run quite hot at 800-900W each, so Agoda can only host 7 or so in each rack.
For data storage, it uses an object store cluster, running on VAST hardware. In this cluster, around 15 PB of raw data and 21 PB of logical data can be stored. More data can be fitted than there is raw storage available thanks to VAST’s data deduplication.
For transactional work, Agoda mostly uses Microsoft SQL server (MSSQL,) running on physical servers optimized for core performance using low-core count and high clock machines. It chose this setup because the Microsoft licensing model has a rather steep per-core cost. Licensing costs are around $7,000 per core for SQL Server’s enterprise edition, so this approach increases the utilization of these licenses.
3. Agoda’s cloud strategy and usage
The remainder of this article is a question-and-answer session between Idan and I. The questions are in italics.
Agoda not moving to the cloud is interesting as it’s a “sibling” of Booking.com, which has started to move to the public cloud. So why has Agoda not done so?
‘I can’t speak for Booking.com, but in some cases I believe companies consider migration to the cloud as an opportunity to “restart” their infrastructure and solve existing scale/capacity issues. Our current position is that we’re happy and quite stable in terms of capacity and performance, so we have no urgent need to make drastic changes to how we do things. For us, a migration for the cloud needs to be an opportunity and not a solution to a problem; it must show benefits in terms of cost, velocity, quality, etc. So far, we haven’t been able to prove such merit in the migration.
Our strategy is to get to a “cloud ready” state. We have neither a “yes, we need to be on the cloud” nor a “no, we will not move to the cloud” position. We want to get to the “we don’t really care where we operate” state; this is our strategy. How do we get there? Firstly, we don’t use expensive setup like SANs (Storage Area Networks). We took a cheaper approach for our hardware stack. By moving all our workloads to Kubernetes, we can easily migrate to a cloud provider, if needed.
Becoming “cloud ready” was why we moved off the HDFS protocol to S3, and why we are hedging our infrastructure ownership by using a few vendors in critical areas. For example, we use VAST as a vendor for storage, rather than self-hosted HDFS clusters.
We are pretty close to our “cloud-ready” goal. We do “lift and shift” exercises a few times every year, which is how we hedge our dependency on our on-prem infrastructure. We’re ready to move if some disaster were to strike when access to the infra was lost, for example.
There’s a lot of groundwork that goes into these exercises. We work with the cloud provider, set up a fiber connection with them, set up databases there, and do the lift-and-shift exercises. Over the years, we’ve become more efficient in setting up the experiment. For example, initially, we set up virtual machines to run in the cloud and we had to have all those virtual machines running, even when not in use. These days, we use Kubernetes and spin up the containers when we do the exercise.’
What about using the cloud to “scale out” your operations, for example during peak loads?
‘We actually looked into scaling loads out, but this turns out to be not so simple. Our original idea was to spin up the cloud only for peak traffic, or during high traffic periods. However, it turned out that providers are not particularly optimized to guarantee 50,000 cores being available for 2 hours usage per day. And this makes sense from their point of view; after all, what would they do with all those cores the rest of the time?
There are some use cases where we do use the public cloud. An example is CI/CD, which is a smaller use case, and we’re okay with spending more than if we ran jobs on-prem. In return, we have guaranteed SLAs on how quickly builds will finish, regardless of how many builds happen in parallel. Having these SLAs means our developers can iterate quicker.
For massive production use cases when we would need to put in a large ask for a cloud provider; it would not make financial sense without a significant baseline budget commitment.
Even with fiber connections, it’s hard to have fast enough connections from a service to the database. So if we want to keep our databases “warm” on the cloud at all times, that would incur a baseline cost. This cost is the latency between databases like our MSSQL, Couchbase, ScyllaDB and other instances, and our microservices.
While we could rebuild our systems to handle higher latency from the authoritative database without much user impact, the centralized cache engines would need to be kept “warm” in some way within the cloud. This baseline cost is also why we don’t “burst to the cloud” for production services, at present.
We have approaches for handling traffic spikes without scaling to the public cloud. They include:
- Shifting traffic between datacenters. This works well as our data centers have different peak schedules in different regions.
- Degrading features for exceptional spikes, instead of buying more servers to ensure we can handle any type of spike.
- An idea for the future is that in the case of extreme spikes, we would shift part of this load to the data engineering DC. Currently, we do not shift load to the data engineering clusters during spikes.’
4. The cloud or your own data centers?
For small enough companies, it’s pretty clear that onboarding to the cloud has lots of advantages. But what advice would you give a scaleup or a midsize company evaluating whether to operate their own data centers, or to onboard to the cloud?
‘Use knowledge-driven decision making. Decisions that come from ignorance are poor ones, such as “everyone else does it, so we should as well,” or “what we have works and I’m afraid of trying this new technology.” On the other hand, decisions that come from actual knowledge and understanding are good decisions! So gather the knowledge and make sure it applies to your situation. Avoid cargo culting – when you imitate things you don’t understand!’
Have the expertise and investment to operate on-prem
‘Get into a position where you don’t have to care too much about whether or not you are on the cloud. The best position to be in is not caring about whether you run your own infrastructure, or onboard to the cloud. Get your application stack in a shape whereby you can operate in either setting. Then you can objectively make infrastructure changes much quicker than if you’re locked in to on-prem or the cloud.
Be “cloud-ready” while running on-prem. Even if you run on-prem, ensure you use technology you can shift to the cloud relatively easily. For example, using Kubernetes as orchestration and the S3 protocol for data, are all choices we made in running our stack on-prem, which are also “cloud-ready” choices.
Avoid software that locks you in. Proprietary software can lock you into a given provider, making it very hard – and expensive – to move.
Be aware of the margins of each cloud service. Are the charges worth it for your use case? The cloud is not just for getting machines to use; it includes an ecosystem of services as well.
At least some of these services are running software that is easy to maintain and run and have no licensing cost. Still, the providers are still incentivized to “scare” you into believing you cannot manage it by yourself. It’s important to make that judgment with your own team and come to a knowledgeable decision.
The focus on the expertise needed and whether you can manage it yourself, is a kind of fear-mongering that has been very strong in selling the cloud. In some cases this makes sense. For example, the US is an aggressive market where super talented people who know the cloud services inside-out can work for the companies that build those services, and great engineers often prefer to work at the “source.” But then, when you look at Agoda, we are pretty much the only company in Thailand that does anything like this so in-depth.
If I’d come to Silicon Valley to convince a talented developer to come to Thailand to work for Agoda, it would be hard. But for developers based in this part of the world, we’re a shining star doing interesting, exciting and challenging stuff, plus we’re almost the only ones going all the way down to infrastructure-level. In our geographical area, we’re unique.’
When you’re already on the cloud
‘Don’t let teams use whatever they want in the cloud. Here’s the thing, onboarding is always super easy. However, offboarding can be hard to impossible! This type of lock-in is the biggest risk of the cloud in my view. One way to work around lock-in is to force the use of at least two cloud providers across the organization, and only allow onboarding to services on one cloud provider if they can be migrated to the other provider.
Be conservative about adding new technology dependencies. Don’t add one unless it really adds a new capability you cannot support in your current stack. In other words, don’t increase the stack size itself unless you really have no choice!
The same goes for taking on cloud service dependencies. I’ve seen a lot of cloud services be acquired, or suddenly pivot, or be shut down. When this happens, if you have a dependency on such a service, you are left with an “ultimatum” of needing to find a new solution, and you start from scratch in the search. This is a very real risk that’s worth calculating.’
Takeaways
Thanks very much to Idan for generously sharing so much detail about Agoda’s journey in operating on-prem, and its thinking about using the cloud. Although Idan did not ask me to mention this, I will add that Agoda is hiring in several locations across Asia.
Here are few takeaways worth taking from Agoda’s journey, especially as we contrast it to that of Uber’s.
Every business has unique constraints. Agoda operates in Asia, where the cost of labor is lower than the US and Europe, but where public cloud costs are higher. The company has been in business for almost 20 years and has always managed its own infrastructure.
It has hardware buyers, people installing and maintaining machines, and folks building the software infrastructure layer to run on top of virtual machines. Agoda employs tens of people to manage the infrastructure layer, and probably around 100 people who work on various parts of infrastructure and DevOps. Here’s a breakdown of employee numbers from Idan:
- Tens of people (between 10 and 30) maintaining hardware
- 25-30 people maintaining data infrastructure like Kafka or RabbitMQ.
- 20-30 people working in the database administration area
- The teams who build and maintain solutions like Fleet
If your company is in a similar position in terms of infra needs, and engineering headcount; and has made similar investments in infrastructure, then you might also be able to set up and operate your own infrastructure. If not, it doesn’t mean you cannot! Treat all details in this article as examples of approaches, not instructions which your company should closely follow.
The above was about a third of the topics discussed in two subscriber-only deepdive articles about Agoda’s private data centers. The full article series covers these additional topics:
- Internet service provider (ISP) basics. What are tier 1, 2 and 3 ISPs? Why does it matter? And why does Agoda connect to a Tier 1 one?
- Data center tiering. How tiers 1-4 for data centers measure up, and which tiers do popular cloud providers certify as? Why does Agoda co-locate with Tier 3-or-above?
- The evolution of data centers at Agoda. From blade servers and Windows machines in 2012, to an in-house, Kubernetes-based orchestrator development system today.
- Data centers (DCs) and availability zones. How does the company organize its two regions, and which services use active-active or active-passive DC setups?
- The application stack inside the private cloud. Fleet, Buckbeak, Agoda’s detailed data stack and bespoke developer portal.
- To move or not to move to the cloud. How Agoda knows if it’s time to move away from on-prem servers. Are location-based expenses keeping the company off public clouds?
- A surprise advantage of hiring software engineers. Owning their own stack end-to-end comes with unexpected hiring benefits, when attracting developers.
- Agoda’s learnings from operating its own DCs. The importance of standardizing, and why to minimize your tech stack.
Read the full article series here.
Subscribe to my weekly newsletter to get articles like this in your inbox. It's a pretty good read - and the #1 software engineering newsletter on Substack.