Incident Review and Postmortem Best Practices
One reason incidents are important is that they often reveal the real state of products, teams or organizations, which is often very different from the imaginary picture that engineering leaders have in their heads. Transparent incident reports and a good incident-handling strategy can inject much-needed realism into the development process. It’s hard to brush aside incidents that have caused specific damage, indeed these incidents are often powerful ways to make cases for work that would otherwise be delayed indefinitely.
The only certain thing about outages is that they will always happen. Everything else is up to us. How much effort do we put into preventing them, or into mitigating them quickly, or learning from them?
I’ve talked with dozens of engineers at a variety of companies and have found that no one is fully happy with how they are handling incidents.
In this issue we cover:
- Common incident handling practices across the industry. What are the trends on how tech companies approach incidents today?
- Incident review best practices. What are processes, tools and approaches that we can point to as sensible practices?
- Incident review practices of tomorrow. A few teams and companies have moved beyond what we’d call the best practices of today. What is their approach and how is it working?
- What tech can learn from incident handling in other industries. Incidents are not unique to tech; fields like healthcare, the military and many others have a long history of efficiently dealing with incidents. What can we learn from them?
- Incident review/postmortem examples and templates. A selection of case studies you can get inspiration from and 🔒subscriber-only postmortem templates.
The oncall process – monitoring and alerting – is beyond the scope of this article. We cover what happens starting from when an outage or incident is confirmed.
This article was originally published in the Pragmatic Engineer Newsletter. In every issue, I cover challenges at big tech and high-growth startups through the lens of engineering managers and senior engineers. Subscribe to get weekly issues.
How Companies Handle Incidents
More than 50 teams have shared information on how they respond to outages, and what happens afterwards. See all aggregated results here.
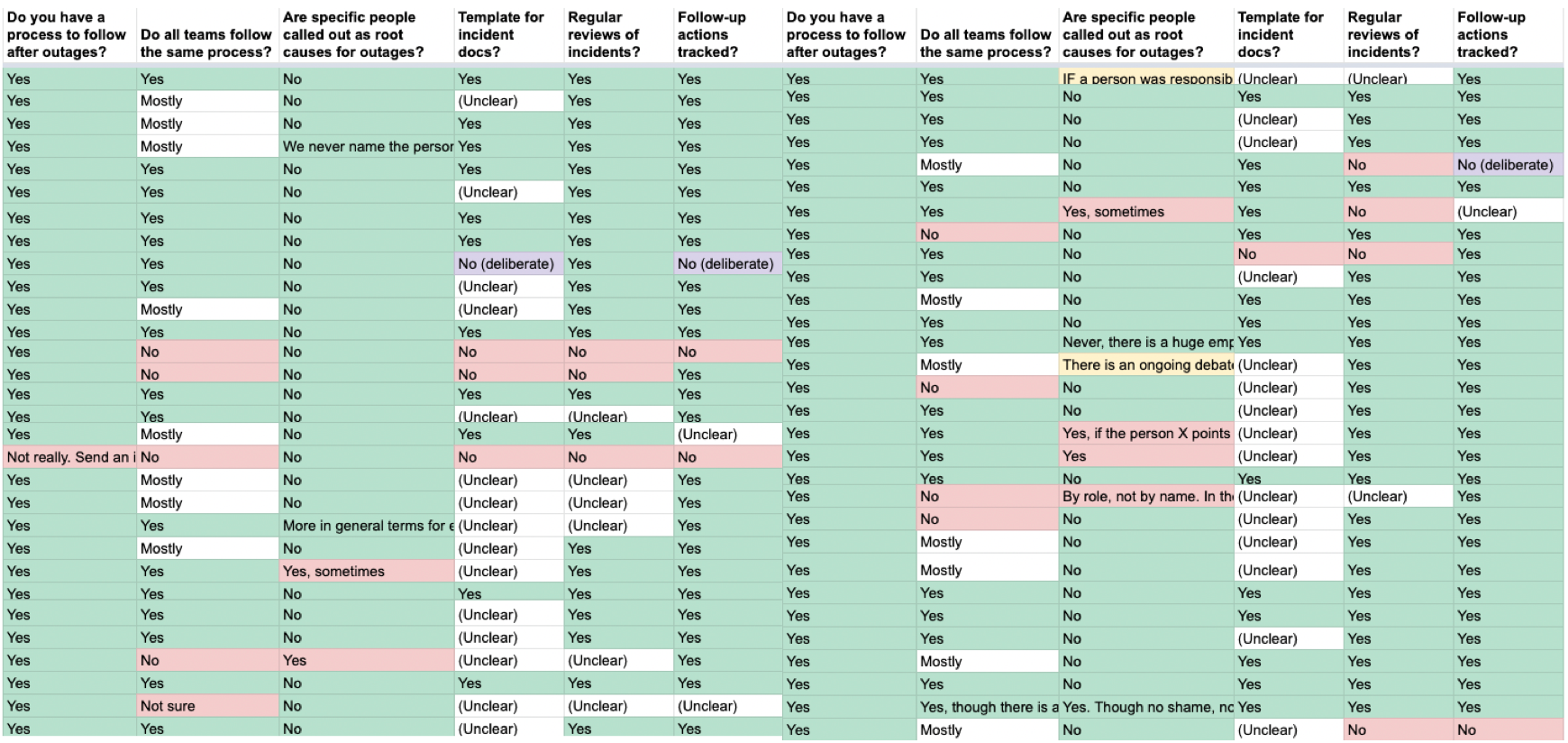
98.5% of companies sharing details have an incident management process in place. The only exception was a Series C property management company which used an ad-hoc process on top of email, to manage incidents. I was expecting more variation on the process, the tooling and the steps, but there were large overlaps across companies. This might be explained by selection bias, meaning the survey was mostly filled out by engineers whose teams already take incidents seriously.
The majority of companies sharing data follow a process that can be summarized like this:
- An outage is detected. This could happen following an automated alert, or someone noticing that something is “off”.
- An incident is declared. An engineer – often the on-call engineer – confirms that an outage is happening. They follow an agreed process to declare this incident, which is often a mix of declaring it over chat, and sometimes opening a ticket in a system used to track incidents.
- The incident is being mitigated. During mitigation, the engineers involved provide updates. Some companies have more processes around this than others; for example, making it clear who the Incident Leader or Incident Commander is, or expecting regular updates to stakeholders when high-priority outages happen.
- The incident has been mitigated. Everyone breathes a sigh of relief.
- Decompression period. There is rarely an expectation for engineers to immediately kick off root cause investigation. This is especially true when the mitigation happened outside business hours, say in the middle of the night. However, many companies have a target window to complete analysis within 36-48 hours, which puts pressure on engineers to shorten this decompression time.
- Incident analysis / postmortem / root cause analysis. Almost every company calls the investigation that follows by a different name. The idea is the same, the people involved in the incident get together one way or the other, and summarize what happened, and what the learnings are.
- Incident review. For outages with a large enough impact, a bigger group reviews the analysis put together in the previous step. Some companies have dedicated incident management teams running this process, some have weekly or bi-weekly meetings with some managers present, while others do it ad hoc.
- Incident actions tracked for follow up. In the analysis and review, teams come up with improvements on how to either prevent similar outages, reduce the time to mitigate, or the impact of the outage. During the review, these actions are captured, and added to the roadmap or backlog of the teams owning these.
What tooling do teams use when handling incidents? Based on survey responses, these were the most common mentions:
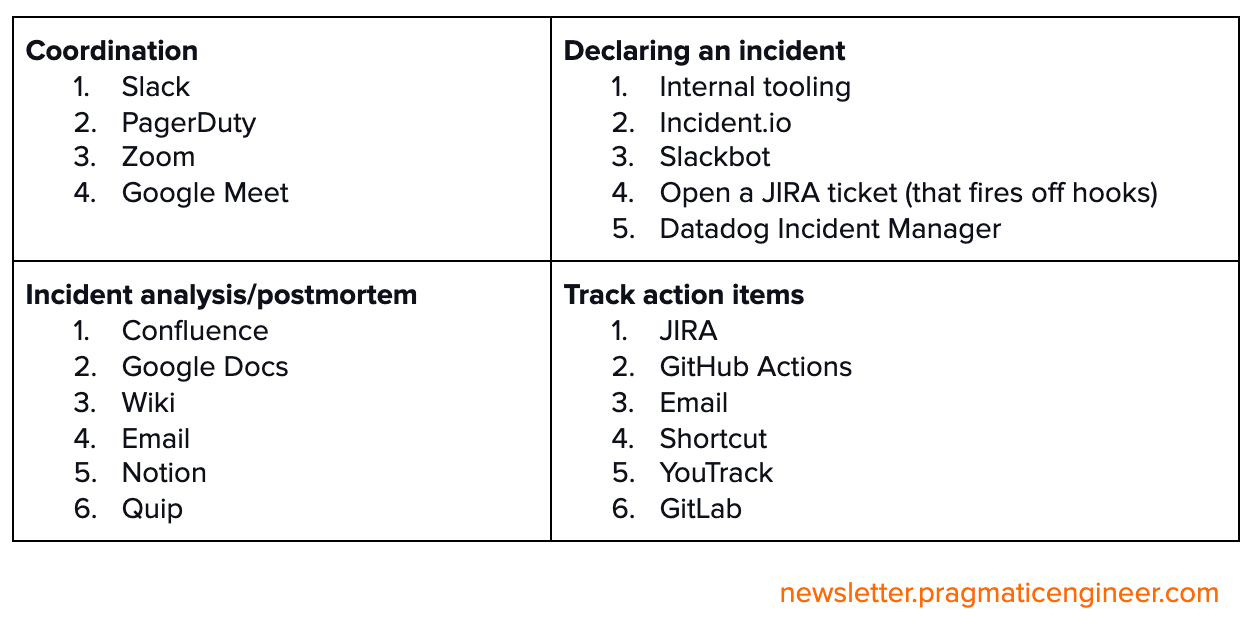
Less common approaches that a few companies mentioned:
- Research the same day, postmortem the next day. “Our team does a little research right afterwards, while the incident is still fresh. We then start the postmortem process the next day. It’s down to the engineers to decide how they go about it; the point is they don’t need to start the postmortem right away.”
- Dedicated decompression time. “The team which owns the service/system that failed takes time out from regular work to decompress (if it was a big outage) and to work on post-incident review and immediate follow-up actions.”
- Create low priority incidents to broadcast risky migrations. Some companies with incident systems that are used to check the health of systems, often create low-priority incidents to raise awareness for risky migrations that could result in temporary issues, but which they are actively monitoring for.
Incident Handling Best Practices
What are practices that stand out in their effectiveness, when we think of incidents?
- Encourage raising incidents, even when in doubt. It can be stressful to decide whether or not an incident should be created when something looks “off”. At the same time, many incidents are either delayed in their response, or are missed completely because someone did not ring the alarm when they had a nagging suspicion. Create a culture where it’s encouraged to raise an incident. Even if it turns out to not be an outage, it’s worthwhile learning to investigate why it felt like something was wrong.
- Be clear on roles during incidents. Make it clear who is in charge of mitigating the incident, and who should communicate with stakeholders. Many places call this role the Incident Commander. The role of leading mitigation and communicating might be the same. However, for high severity outages, or when many stakeholders need to be kept in on how it’s going, it might make sense to separate them.
- Define incident severity levels ahead of time. Have a shared understanding of what makes an outage more ‘important’. Write down the definition, and use the same definitions across the organization. Most companies define severity levels based on how customers might be impacted, and the impact radius based on what percentage of these customers are impacted. Over time, you’ll probably need to update your definitions as new types of incidents occur.
- Have playbooks ready for common incidents, and make them easy to locate and use. Playbooks could be referenced as part of the alert, or listed at a place where it’s easy for the oncall engineer to find them. Playbooks help with onboarding new members to the rotation, while knowing what to check for – and in what order – can help mitigate outages faster.
- Leave time for engineers to work on an incident review/postmortem. While it’s always possible to rush this process, you’ll get lower quality reviews if you do so. Instead, give people the space to get together and discuss what happened, and aim for all those involved to have their say.
- Dig deeper when looking into root causes of the incident. Don’t stop at the first and often obvious, potential reason. Ask questions to understand how various factors could have contributed to the outage, and what are the things that contributed to those factors.
- Share incident analysis and learnings with a broader group, instead of keeping it within the small group which reviews incidents.
- Find and use tools built for efficient incident handling. There are companies whose incident review tooling is email-based, and even a simple approach like this can work well enough. However, if you use tools that support the understanding of common incident workflows, you’ll see less confusion, and less tribal knowledge being needed to handle outages. Many companies build their own tooling, and there’s a world of vendors and open source services teams can use. Contributors to this article include engineers from incident handling tools incident.io (dedicated incident response tools), Jeli.io (incident analysis platform) and Blameless.com (end-to-end platform). Do your research: you’ll find plenty of others as well.
Blameless reviews/postmortems are worth talking more about. When doing a root cause analysis, avoid making it seem like a single person is responsible for the incident. Most outages will be caused by configuration or code changes that someone did, and it’s very easy to find out who it was. However, it could have been anyone else on the team.
Instead of directly or indirectly putting the blame on one person, go further and look at why systems allowed anyone to make those changes, without providing feedback. If the conditions that allowed the incident to happen are unaddressed, these conditions could trip up someone else on the team in future.
Some people resist the idea of “pushing” the use of blameless postmortems across an organization. “Will this not lead to a lack of accountability?” they ask.
But accountability and a blameless culture are two separate things in my view, which can – and do – go hand in hand. Accountability means people take responsibility for their work, and when things inevitably go wrong, they take ownership of fixing things. A blameless approach recognizes and embraces that it’s counterproductive to fault someone for doing something they were unaware would cause an issue. This is especially the case when those people take accountability for addressing the reasons that led to the issue.
Well-run incident review meetings are key to sharing context with all involved, and to coming to better learnings. Here is a structure that some of the best run review discussions followed:
- Do the work upfront. By the time of a meeting, the people involved in the outage should have come together, discussed the incident and their take on it, and put together resources that can be used to give others context.
- Level set in the beginning. Don’t dive in straight to the incident. Start with sharing high-level details and context, so everyone in the room gets on the same page.
- Walk and talk through the timeline as it happened. Don’t just run a script, but talk through what was happening. What looked weird? Why did you have a nagging concern? If you’re in a review, jump in and ask questions. Understanding how things unfolded is much more important than most people realize.
- Keep it blameless. Avoid referring to any one person being the one “to blame” for the incident.
- Recognize what went well, and what can be improved. Don’t focus only on what’s lacking, but call out actions, processes, systems that worked well, some of which might have been learnings from another incident.
- Track actions as they come up. As ideas come up for things that can be changed or improved, keep a running list of these.
- Consider separating reviews and action items meetings. By focusing on "what can we learn" in the first review meeting, much better improvement actions emerge in a second meeting focused on action item identification, held a day or more later.
- Record the meeting so those who missed it can catch up, and have the full context.
- Open up the meeting to a wider group, so people with additional context, or those curious can join. This practice can help with transparency and spreading of information.
I sat down with Chris Evans, co-founder and CPO at incident.io, formerly head of platform at Monzo. I asked him which other practices he’s seen adopted by engineering teams which are great at incident handling. Here’s what he shared:
- Avoid “blameless buck-passing”. When a high severity outage happens, there is often pressure from above on the team to “do everything so this can never ever happen again.” This approach, in turn, can turn reviews into blameless buck passing exercises, in which those involved try to shift any implied blame away from them or their team, to somewhere else. On the surface, it’s a blameless process. In reality, it’s a poor experience for everyone involved and creates unnecessary pressure.
- Remove the pressure of it “never happening again” and of all reviews needing to have action items. Do these two things and you’ll have far more effective incident reviews.
- Give “soak time” after incidents. After the outage, leave time for the team to talk and soak up what really happened.
- Think of incident reviews as a process, not as an artifact. Too many teams focus on writing the artifact, basically a report, instead of the review being a process that starts before you write anything down, and does not end when a document is complete.
- Treat an incident as an “aha moment”. Every incident sheds light on something the team did not know before. What was it?
- Consider retiring the title “postmortem”. Postmortem means examining a body to determine the cause of death. This has a grim association, and starts with the assumption that something terrible has happened.
Beyond the Best Practices of Today
Observability platform Honeycomb stood out in their responses to my survey. They were one of the few firms which are moving away from templates and do not track action items. Unlike most other teams which want to do this, they actually took the step.
From many other teams, I would have interpreted this as trying out something that might or might not work. However, Honeycomb handles huge amounts of data, and provides stricter Service Level Agreements (SLAs) than most of their competitors. They also take reliability very seriously, so much that a 5-minute delay in data processing is an outage they publicly report.
I asked Honeycomb engineer Paul Osman why they made this shift, and how it’s working out. Paul shared how two years ago, they noticed that action items coming up during reviews were not particularly interesting findings; they were mostly things the team was going to do, anyway.
Focusing on the learning during incident reviews, over explicitly tracking action items, has been the biggest shift, Paul shared. Teams and individual engineers still create their own tasks, not just for incident reviews, but for everyday work. They’ll also create those tasks even if there’s not an incident review. Paul said:
‘For us, the review is more about “who knew what when and how did they know it?” and “how did our systems surprise us?” instead of “what action items can we extract from this?”
‘Most of the interesting insights we’ve found are in a different category from tasks. They’re things like “new traffic patterns can show up as red herrings when debugging” or “Hey, this person is needed whenever we have a problem with this system, we should schedule someone to pair with them so they can go on vacation”.
Honeycomb have left behind some practices that outlived their usefulness, and seem to be better off for it. However, I’d add that they’re still a relatively small group – around 35 engineers – at a place where everyone operates with high autonomy.
Moving on from the Five Whys method for gathering more information, is another approach used by teams which are great at incident handling. The Five Whys is still considered as a best practice by many teams and is a common way to run the root-cause analysis process. The idea here is to ask “why” in succession, going deeper and uncovering more information each time.
The framework is very easy to get started, when teams don’t do much digging into incidents. However, as Andrew Hatch at LinkedIn shares in the talk Learning More from Complex systems, there are risks to relying on the Five Whys:
“The danger of the Five Whys is how, by following it, we might miss out on other root causes of the incident. (...) We’re not broadening our understanding. We’re just trying to narrow down on one thing, fix it, and hope that this will make the incident not happen again.”
John Allspaw also advocates against using the Five Whys in his The Dangers of The Five Whys article. He says that asking “why” is a sure way to start looking for a “who”, and to start looking for who is to blame for the outage.
Instead of asking “why?” multiple times, consider asking “how did it make sense for someone to do what they did?”. Then dig deeper in gathering the context that made the choices logical, in the context of the people acting. Here are some other questions to consider asking to run healthy debriefs.
Take a socio-technical systems approach to understand the outage. A root cause analysis or the Five Whys approach can be appealing because they simplify a post-incident effort, but they will not address the deeper systemic issues within your system, says Laura Maguire, Head of Research at Jeli.io.
Socio-technical systems approaches look at both the technical aspects – what broke – and the ‘social’ aspects; how the incident was handled. This gives an oncall team deeper information about software component failures. It also surfaces relevant organizational factors, such as who has specialized knowledge about different aspects of the system and which stakeholders need updates at what frequencies, in order to minimize impacts to their areas of the business. Some guidance for conducting a systemic investigation:
- Use human error as a starting point for an investigation. For example, if an engineer appears to have made a mistake, look at the processes they used, the training they received, how frequently they interact with that part of the system or codebase, their workload, their oncall schedule and other relevant details that put an error into the broader context. Sidney Dekker, founder of the Safety Science Innovation Lab advocates for this approach in the book, The Field Guide to Understanding 'Human Error'.
- Consider organizational factors. Do teams have a headcount that allows them to execute on their roles and responsibilities in a manner that isn’t burning people out? Are there legacy systems that haven’t been dealt with? Is ownership of services clear?
- Gather contextual information relevant to the event. Questions such as “Were you on call?”, “How did you get brought into the incident”, “Have you worked with this team before?” can reveal important information about the ad hoc or informal ways teams adapt to cope with unusual or difficult outages.
- Encourage participants to recount their experiences as they happened, not as they think they should have responded in hindsight. Focusing on what happened can surface partial or incomplete mental models about how the system works. It can reveal new ways of approaching a problem or monitoring anomalous behaviour and can help a team share specialized knowledge. If psychological safety is present, sharing these stories publicly can allow others to hear what may not be apparent to everyone else.
- A systemic investigation is about asking a different set of questions and recognizing that individual actions and decisions are influenced and constrained by the system of work they take place in.
Incident Review Practices of Tomorrow
I sat down to talk about the future of incident management with John Allspaw, who has been heavily involved in this space for close to a decade. He was engineer #9 at Flickr at the time of Flickr’s massive growth phase. He then became the CTO of Etsy, where he worked for seven years.
For the past decade, John has been going deeper and deeper into how to build better resilient systems. He enrolled in Lund University in Sweden in the Human Factors and Safety program, a program where some of the leading thinkers in resilience engineering seem to have crossed paths. He has founded Adaptive Capacity Labs, which partners with organizations that want to further improve how they handle and learn from incidents.
As we talked for an hour, I kept being surprised by the depth of his understanding of resilient systems. It slowly made sense why he spent so much time studying non-tech related subjects, all connected to resilient engineering systems. John also exposed a world of decades-old research outside tech that I would have never thought to look to as inspiration to build better, more reliable systems, but which perhaps we all should. Here’s a summary of our conversation. My questions are in italics.
Why have you been spending so much time on the incident space?
‘Incidents create attention energy around them. When something goes wrong, people pay far more attention to everything around the event than when it’s business as usual. This is also why incidents and outages can be a catalyst to kicking off larger changes within any organization, not just tech companies.’
What is your view on industry best practices which many companies follow, like templates, incident reviews, follow-up items?
‘Incident handling practices in the industry are well-intentioned, and point in the right direction. However, these practices are often poorly calibrated. We talk a lot about learning from incidents, and some learning is certainly happening. However, it’s not happening as efficiently as it could.
‘We often confuse fixing things fast with learning. Take the incident review that most companies follow. There’s an hour, at most, to go through multiple incidents. There is often more focus on generating follow-up items than learning from the incident. In fact, most people seem to think that by generating follow-up items, learning will also happen. However, this is far from the case.
‘When we talk with companies, we ask them to describe how they handle incidents. They jump in, talk about how they detect outages, how they respond, who plays what role, and which tools they use. They’ll often mention cliches like “we never let a good incident go to waste.”
‘However, most teams cannot describe a major incident in detail. We typically ask them to talk us through a specific incident, instead of sharing their generic approach. The answer is almost always along the lines of there’s a document, or a ticketing system where this is written down. However, when we find and start reading this document, it’s usually a disappointment and does a poor job in conveying takeaways.
‘Most incidents are written to be filed, not to be read or learned from. This is what we come across again and again. Teams go through incidents, they file a report, pat themselves in the back, and think they’ve learned from it. In reality, the learning has been a fraction of what it could have been.
‘The current incident handling approaches are only scratching the surface of what we could be doing. In several ways, tech is behind several other industries in how we architect reliable systems.’
What Tech Can Learn From Other Industries
What can we as software engineers learn from other industries?
‘Luckily, we have decades of studies on incidents and reliable systems across several industries. And there are plenty of applicable learnings that apply to tech.
‘A common myth is that distributing learnings from incidents is the biggest blocker on improving more. Many teams and people will believe that if only they find a better way to share incident learnings – like make them easier to search or email them out to a larger group – then this will solve the issue of the organization improving from them.
‘However, this belief has been refuted by research many times. The key challenge is the author of a document cannot predict what will be novel or interesting for the reader. Whoever is writing the incident summary will not be able to tell what information will be well-known to the reader. The person writing the incident summary will also often not write down things they assume everyone else to know. However, many readers will not be familiar with them.
‘Studies repeatedly show that experts have a hard time describing what makes them an expert. This applies to incidents; experienced engineers who mitigate incidents efficiently will have a hard time describing what it was that allowed them to act as swiftly as they did.
‘Much of how we handle incidents is tacit knowledge, that which is not explicit. The question of “how do we build a better incident handling culture?” is not too different from “how do we help people become experts on a topic?”. And the answer needs to go beyond writing things down. A good example is how, to learn to skate, you cannot just rely on reading books about skating.’
Before I talked with John, I doubted that tech had anything to learn from other industries. ‘We’re in software, in tech, building things that have never been built before’, I thought. Look at mobile phones, cloud computing or Snapchat; none of this has ever existed!
However, the more we talked, the more it struck home how outages or incidents; stressful situations when something goes wrong, are not unique to software. In fact, often they don't have anything to do with software. These types of unexpected, disruptive events have been happening since before the invention of the wheel. So of course it makes sense there is an accumulated knowledge on how to prepare people for an incident they are yet to experience.
My biggest takeaway talking with John was how a written culture is not enough to create a great incident culture. Writing things down is important, but it won’t cut it alone.
I remember the best oncall onboarding process we had at Uber. It had nothing to do with documentation. It was a simulation of an incident. The facilitating team deliberately disrupted a non-critical service similar to an incident that happened in the past. The people being onboarded knew this was not a real incident, but they were called into a Zoom call in which one of them was named as Incident Commander and the facilitators played along. The team then did a debrief and analyzed what they could have done differently. This exercise achieved far more than any studying of documentation could have.
I do not have data to base this on, but it felt to me like the people who went though this simulation were far more prepared for the real thing. It felt like they had more confidence going on their first oncall, as they had already been through an incident.
This approach got me thinking. ‘Is this why the military does training exercises, despite the high cost?’ John did not answer, but asked the question: ‘Why do you think they do it? Would they do so if reading books or watching videos got them a similar result?’
There’s a lot that we in the software tech industry can learn about how to build resilient systems, by learning about how other industries have been building resilient systems.
The Opportunity to Build More Resilient Systems
As our conversation closed, John mentioned how he thinks the software industry is, in some ways, ahead of most other industries in building resilient systems. He told me how he invited a person to the Velocity conference, one focused on resilience, performance and security in tech. This person spent decades researching resilient systems in healthcare, and assumed they would teach the audience. Instead, this person was amazed at how much they had to learn from tech. As John put it:
‘No other industry has as much, nor as detailed incident data available, as tech does. After an outage happens, engineers have access to code and configuration changes, logs and analytics, often down to the millisecond. You have all this data without having to do much preparation, or go through obstacles to get this data.
‘Compare this to, for example, the medical field. There, you have to do huge amounts of preparation to get data on what happens in an operating theatre. You need to install cameras and microphones. You get permission from all parties to record. You operate the recording equipment, then transfer all the data for processing after the operation.
‘Access to data is far more strict in, for example, the aviation industry. Let’s say you want to investigate a plane near-miss incident. To access the logs, you need to start a special process, and after many approvals, you can talk with the pilot only in the presence of a union representative, and potentially a lawyer. If you forgot to ask something relevant, you need to start the process again.
‘Most engineers believe progress in the software industry means progress in how we build software. However, I believe the real progress is how we get more and more data to see how incidents unfold to the point that we’ll be able to answer the question: what made this incident difficult?’
Software organizations already have all the data they need to improve how they operate, we both concluded. This is a massive advantage compared to all other industries.
I was left wondering, do we realize the privileged position tech puts us in, of having both the data to work with, and the autonomy to do so? And for those who do realize, will we take the opportunity to create much more resilient systems, challenging the best practices of 2021, and pushing ahead to a world where we use incidents to learn and adapt, not just track action items?
Great Incident Review Examples
Few things better show the privileged status of tech than how we already have access to some of the best incident reviews ever written. Companies from Cloudflare, through GitLab and many others, have made these available for anyone who wants to read them. Do keep in mind that public blog posts about incidents are not the same as incident analyses intended for an organization to learn from, and will often not represent the whole story.
The Verica Open Incident database built by Courtney Nash is the most exhaustive public incidents database you can find, and one I’d suggest browsing and bookmarking.
Additionally, here are a few incident analyses that I especially enjoyed reading:
- GitLab database outage in 2017. A very thorough, transparent, and easy to read report. I especially like how they added a follow-up on how the team member is doing who gave the command that started the outage.
- Cloudflare outage in 2019 that brought down core proxying, Content Delivery Network (CDN) and the Web Application Firewall (WAF). Cloudflare outage writeups are always pleasant and educational to read, with occasional stories, lots of details, and an easy-to-follow structure. This one is no different.
- Slack outage in 2021 as people returned to work on the new year. An easy-to-read summary that goes into details on how the outage unfolded, and how they resolved it, step by step.
- Monzo outage in 2019. Another transparent and detailed writeup.
- GitHub outage in 2018 where the service degraded for over a day.
- The Azure Leap Day bug in 2012 and the secondary outage that followed.
Conclusions
We’ve covered a lot of ground in this issue of the newsletter. Depending on where you are at on your team with incidents, I’ll leave you with one of these pieces of advice:
- If you do not yet follow common industry practices like having a well-defined process for raising an incident, doing regular incident reviews, and recording follow-up items, do give this a go. Start step by step, but try to get to a point where responding to incidents is deliberate, not ad hoc.
- If you already have incident review hygiene in place, challenge yourself to make this better. Do you give “soak time” to teams – the time to process what happened – before doing a review? Are your reviews truly blameless, making people feel good about having gone through an incident, rather than being discreet finger-pointing exercises? Do you have reviews where the goal is not to get to action items, but to discuss learnings?
- Focus on learning over action items, if you want to take incident handling to the next level. As a warning, you should learn to jog before you run. Don’t jump to this step if your team has not gone through all the previous stages. But do look at companies like Honeycomb or people like John as inspiration of how you can focus more on learning, and less on the processes.
- Are you making meaningful changes after incidents? Analyzing why an incident happened is important, but without taking action and making changes, this analysis is not worth much. Often you’ll find the changes you need to make are complex and time-consuming. Are you following through with this work, and making systemic changes to improve the reliability of your systems?
Additional Resources
Resources:
- Aggregated survey results on how teams handle incidents.
- 🔒 Postmortem templates with a lightweight and a heavyweight example.
Further related reading:
- Learning from incidents community (LFI) - a community on incidents, software reliability, and the critical role people play in keeping their systems running,
- The airline safety revolution from The Wall Street Journal. No commercial airline in the US has had a fatal crash since 2009. The story of how an industry came together and changed, to make this happen.
- Markers of progress in incident analysis by Adaptive Capacity Labs. How can you tell if an organization is making progress in learning from incidents?
Further related videos:
- Swim, don’t sink: why training matters for SRE and DevOps practices by Jennifer Petoff, head of SRE education at Google
- Food for Thought: What Restaurants Can Teach Us about Reliability by Alex Hidalgo, director of SRE at Nobl9
- Hard problems we handle in incidents but aren’t recognized by John Allspaw, founder of Adaptive Capacity Labs
Thanks to Chris, John, Laura, Paul, for their input in this article, and Alexandru, John, Julik, Kurt, Miljian, Michał and Marco for their review comments.
Subscribe to my weekly newsletter to get articles like this in your inbox. It's a pretty good read - and the #1 software engineering newsletter on Substack.