Resiliency in Distributed Systems
👋 Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. To get similarly in-depth articles every week, subscribe here.
Understanding the ins and outs of distributed systems is important for both backend engineers and for anyone working with large-scale systems. Large-scale systems can mean systems with high load and high queries per second (QPS), storing a large amount of data, or ones built with low latency and high reliability. These systems are pretty common across both Big Tech and high-growth startups.
One of the most interesting books I’ve found on this topic is Understanding Distributed Systems. The book was written by Roberto Vitillo, who was a Senior Staff engineer at Mozilla, then a Principal Engineer at Microsoft. The second edition of this book was released in February of this year.
The book is structured with these sections:
- Communication. Reliable links, secure links, discovery, APIs.
- Coordination. System models, failure detection, time, leader election, replication, coordination avoidance, transactions.
- Scalability. HTTP caching, content delivery networks, partitioning, file storage, data storage, caching, microservices, control panes and data panes, messaging.
- Resiliency. Common failure causes, redundancy, fault isolation, downstream resiliency, upstream resiliency.
- Maintainability. Testing, continuous delivery and deployment, monitoring, observability, and manageability.
I like how the book works its way from the theory needed to understand distributed systems - communication and coordination - to practical topics like scalability and resiliency. The book closes with topics on maintainability, which is an area I found surprisingly little focus with most books.
I reached out to Roberto asking if he’d be open to sharing a few chapters of the book with newsletter readers, and Roberto agreed to do so. I chose two chapters on resiliency, from section #4. If you’d like to dive deeper into other topics, you can buy the e-book on Roberto’s website, or the print book off Amazon.
In this excerpt, we cover:
1. Downstream resiliency
- Timeout
- Retry: exponential backoff, retry amplification
- Circuit breaker
2. Upstream resiliency
- Load shedding
- Load leveling
- Rate limiting: single process and distributed implementations
- Constant work
Note that - as always - no links in this newsletter are affiliates and I have not been paid to endorse or recommend this book. More in my ethics statement.
1. Downstream resiliency (Chapter 27)
Now that we have discussed how to reduce the impact of faults at the architectural level with redundancy and partitioning, we will dive into tactical resiliency patterns that stop faults from propagating from one component or service to another. In this chapter, we will discuss patterns that protect a service from failures of downstream dependencies.
Timeout
When a network call is made, it’s best practice to configure a timeout to fail the call if no response is received within a certain amount of time. If the call is made without a timeout, there is a chance it will never return, and as mentioned in chapter 24, network calls that don’t return lead to resource leaks. Thus, the role of timeouts is to detect connectivity faults and stop them from cascading from one component to another. In general, timeouts are a must-have for operations that can potentially never return, like acquiring a mutex.
Unfortunately, some network APIs don’t have a way to set a timeout in the first place, while others have no timeout configured by default. For example, JavaScript’s XMLHttpRequest is the web API to retrieve data from a server asynchronously, and its default timeout is zero, which means there is no timeout:

The fetch web API is a modern replacement for XMLHttpRequest that uses Promises. When the fetch API was initially introduced, there was no way to set a timeout at all. Browsers have only later added support for timeouts through the Abort API. Things aren’t much rosier for Python; the popular requests library uses a default timeout of infinity. And Go’s HTTP package doesn’t use timeouts by default.
Modern HTTP clients for Java and .NET do a better job and usually, come with default timeouts. For example, .NET Core HttpClient has a default timeout of 100 seconds. It’s lax but arguably better than not having a timeout at all.
As a rule of thumb, always set timeouts when making network calls, and be wary of third-party libraries that make network calls but don’t expose settings for timeouts.
But how do we determine a good timeout duration? One way is to base it on the desired false timeout rate. For example, suppose we have a service calling another, and we are willing to accept that 0.1% of downstream requests that would have eventually returned a response time out (i.e., 0.1% false timeout rate). To accomplish that, we can configure the timeout based on the 99.9th percentile of the downstream service’s response time.
We also want to have good monitoring in place to measure the entire lifecycle of a network call, like the duration of the call, the status code received, and whether a timeout was triggered. We will talk more about monitoring later in the book, but the point I want to make here is that we have to measure what happens at the integration points of our systems, or we are going to have a hard time debugging production issues.
Ideally, a network call should be wrapped within a library function that sets a timeout and monitors the request so that we don’t have to remember to do this for each call. Alternatively, we can also use a reverse proxy co-located on the same machine, which intercepts remote calls made by our process. The proxy can enforce timeouts and monitor calls, relieving our process of this responsibility. We talked about this in section 18.3 when discussing the sidecar pattern and the service mesh.
Retry
We know by now that a client should configure a timeout when making a network request. But what should it do when the request fails or times out? The client has two options at that point: it can either fail fast or retry the request. If a short-lived connectivity issue caused the failure or timeout, then retrying after some backoff time has a high probability of succeeding. However, if the downstream service is overwhelmed, retrying immediately after will only worsen matters. This is why retrying needs to be slowed down with increasingly longer delays between the individual retries until either a maximum number of retries is reached or enough time has passed since the initial request.
Exponential backoff
To set the delay between retries, we can use a capped exponential function, where the delay is derived by multiplying the initial backoff duration by a constant that increases exponentially after each attempt, up to some maximum value (the cap):
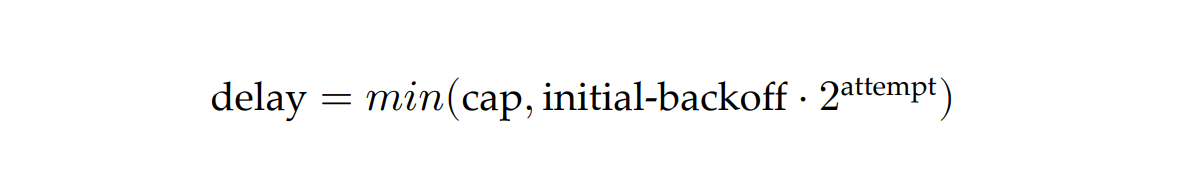
For example, if the cap is set to 8 seconds, and the initial backoff duration is 2 seconds, then the first retry delay is 2 seconds, the second is 4 seconds, the third is 8 seconds, and any further delay will be capped to 8 seconds.
Although exponential backoff does reduce the pressure on the downstream dependency, it still has a problem. When the downstream service is temporarily degraded, multiple clients will likely see their requests failing around the same time. This will cause clients to retry simultaneously, hitting the downstream service with load spikes that further degrade it, as shown in Figure 27.1.
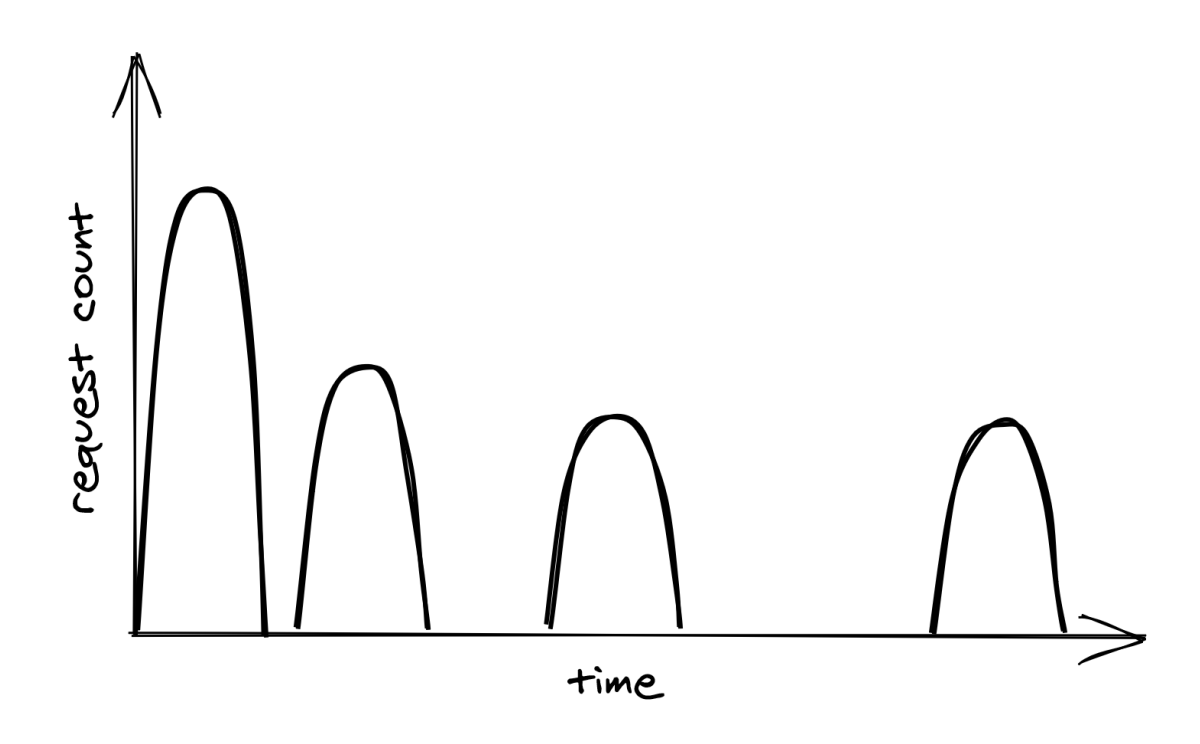
To avoid this herding behavior, we can introduce random jitter into the delay calculation. This spreads retries out over time, smoothing out the load to the downstream service:
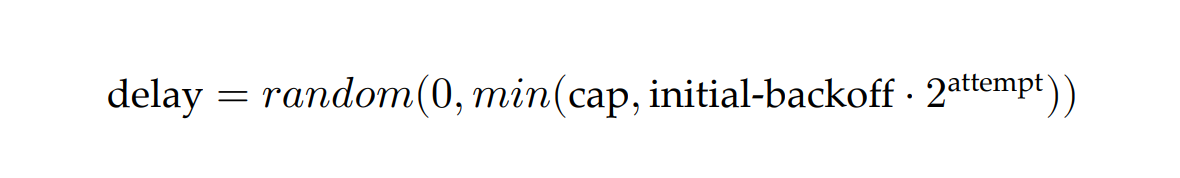
Actively waiting and retrying failed network requests isn’t the only way to implement retries. In batch applications that don’t have strict real-time requirements, a process can park a failed request into a retry queue. The same process, or possibly another, can read from the same queue later and retry the failed requests.
Just because a network call can be retried doesn’t mean it should be. If the error is not short-lived, for example, because the process is not authorized to access the remote endpoint, it makes no sense to retry the request since it will fail again. In this case, the process should fail fast and cancel the call right away. And as discussed in chapter 5.7, we should also understand the consequences of retrying a network call that isn’t idempotent and whose side effects can affect the application’s correctness.
Retry amplification
Suppose that handling a user request requires going through a chain of three services. The user’s client calls service A, which calls service B, which in turn calls service C. If the intermediate request from service B to service C fails, should B retry the request or not? Well, if B does retry it, A will perceive a longer execution time for its request, making it more likely to hit A’s timeout. If that happens, A retries the request, making it more likely for the client to hit its timeout and retry.
Having retries at multiple levels of the dependency chain can amplify the total number of retries — the deeper a service is in the chain, the higher the load it will be exposed to due to retry amplification (see Figure 27.2).
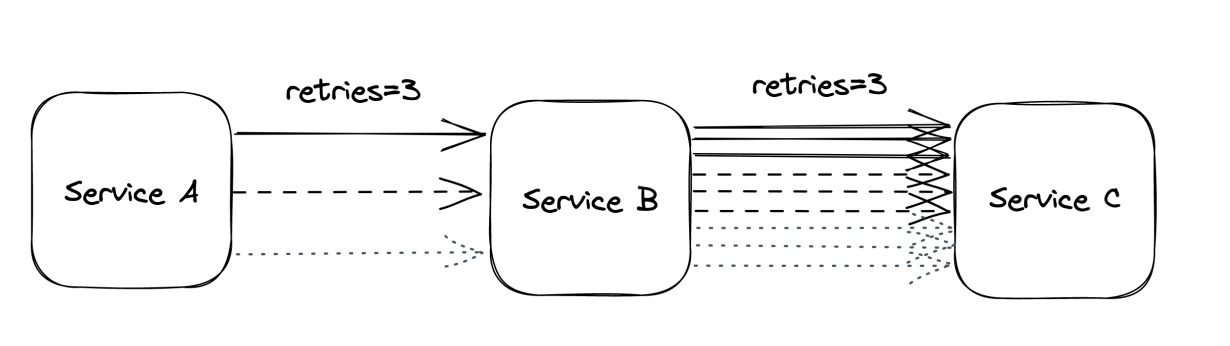
And if the pressure gets bad enough, this behavior can easily overload downstream services. That’s why, when we have long dependency chains, we should consider retrying at a single level of the chain and failing fast in all the others.
Circuit breaker
Suppose a service uses timeouts to detect whether a downstream dependency is unavailable and retries to mitigate transient failures. If the failures aren’t transient and the downstream dependency remains unresponsive, what should it do then? If the service keeps retrying failed requests, it will necessarily become slower for its clients. In turn, this slowness can spread to the rest of the system.
To deal with non-transient failures, we need a mechanism that detects long-term degradations of downstream dependencies and stops new requests from being sent downstream in the first place. After all, the fastest network call is the one we don’t have to make. The mechanism in question is the circuit breaker, inspired by the same functionality implemented in electrical circuits.
The goal of the circuit breaker is to allow a sub-system to fail without slowing down the caller. To protect the system, calls to the failing sub-system are temporarily blocked. Later, when the sub-system recovers and failures stop, the circuit breaker allows calls to go through again.
Unlike retries, circuit breakers prevent network calls entirely, making the pattern particularly useful for non-transient faults. In other words, retries are helpful when the expectation is that the next call will succeed, while circuit breakers are helpful when the expectation is that the next call will fail.
A circuit breaker can be implemented as a state machine with three states: open, closed, and half-open (see Figure 27.3).
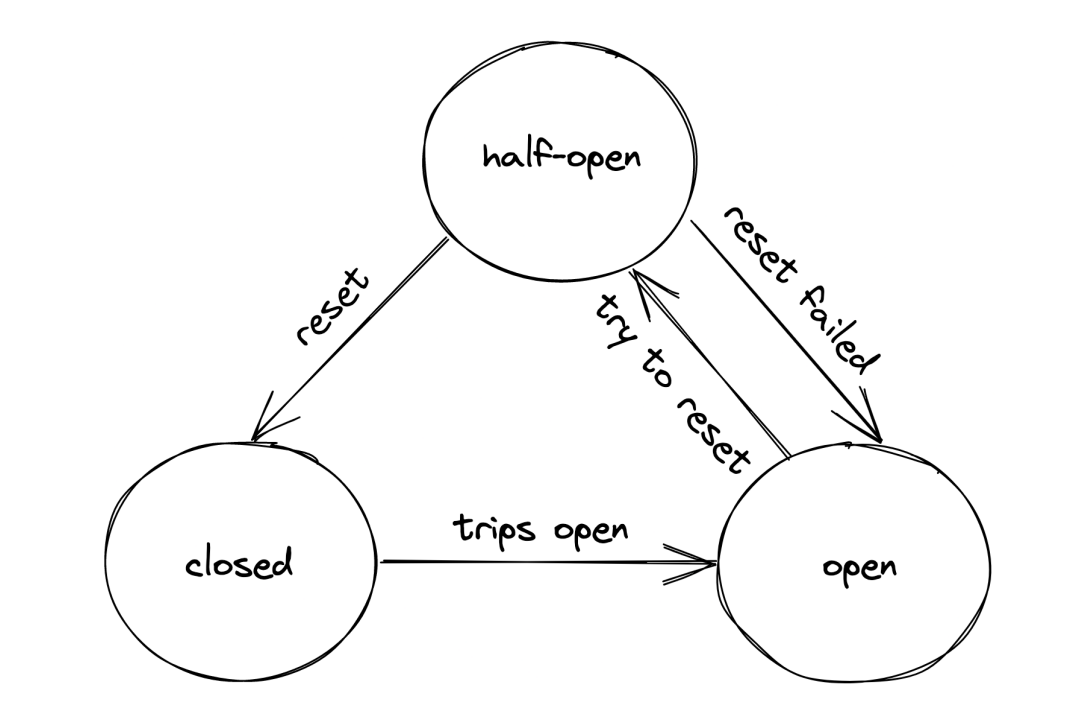
In the closed state, the circuit breaker merely acts as a pass-through for network calls. In this state, the circuit breaker tracks the number of failures, like errors and timeouts. If the number goes over a certain threshold within a predefined time interval, the circuit breaker trips and opens the circuit.
When the circuit is open, network calls aren’t attempted and fail immediately. As an open circuit breaker can have business implications, we need to consider what should happen when a downstream dependency is down. If the dependency is non-critical, we want our service to degrade gracefully rather than to stop entirely. Think of an airplane that loses one of its non-critical sub-systems in flight; it shouldn’t crash but rather gracefully degrade to a state where the plane can still fly and land. Another example is Amazon’s front page; if the recommendation service is unavailable, the page renders without recommendations. It’s a better outcome than failing to render the whole page entirely.
After some time has passed, the circuit breaker gives the downstream dependency another chance and transitions to the half-open state. In the half-open state, the next call is allowed to pass through to the downstream service. If the call succeeds, the circuit breaker transitions to the closed state; if the call fails instead, it transitions back to the open state.
You might think that’s all there is to understand how a circuit breaker works, but the devil is in the details. For example, how many failures are “enough to consider a downstream dependency down? How long should the circuit breaker wait to transition from the open to the half-open state? It really depends on the specific context; only by using data about past failures can we make an informed decision.
Upstream resiliency (Chapter 28)
The previous chapter discussed patterns that protect services against downstream failures, like failures to reach an external dependency. In this chapter, we will shift gears and discuss mechanisms to protect against upstream pressure.
Load shedding
A server has very little control over how many requests it receives at any given time. The operating system has a connection queue per port with a limited capacity that, when reached, causes new connection attempts to be rejected immediately. But typically, under extreme load, the server crawls to a halt before that limit is reached as it runs out of resources like memory, threads, sockets, or files. This causes the response time to increase until eventually, the server becomes unavailable to the outside world.
When a server operates at capacity, it should reject excess requests so that it can dedicate its resources to the requests it’s already processing. For example, the server could use a counter to measure the number of concurrent requests being processed that is incremented when a new request comes in and decreased when a response is sent. The server can then infer whether it’s overloaded by comparing the counter with a threshold that approximates the server’s capacity.
When the server detects that it’s overloaded, it can reject incoming requests by failing fast and returning a response with status code 503 (Service Unavailable). This technique is also referred to as load shedding. The server doesn’t necessarily have to reject arbitrary requests; for example, if different requests have different priorities, the server could reject only low-priority ones. Alternatively, the server could reject the oldest requests first since those will be the first ones to time out and be retried, so handling them might be a waste of time.
Unfortunately, rejecting a request doesn’t completely shield the server from the cost of handling it. Depending on how the rejection is implemented, the server might still have to pay the price of opening a TLS connection and reading the request just to reject it. Hence, load shedding can only help so much, and if load keeps increasing, the cost of rejecting requests will eventually take over and degrade the server.
Load leveling
There is an alternative to load shedding, which can be exploited when clients don’t expect a prompt response. The idea is to introduce a messaging channel between the clients and the service. The channel decouples the load directed to the service from its capacity, allowing it to process requests at its own pace.
This pattern is referred to as load leveling and it’s well suited to fending off short-lived spikes, which the channel smooths out (see Figure 28.1). But if the service doesn’t catch up eventually, a large backlog will build up, which comes with its own problems, as discussed in chapter 23.
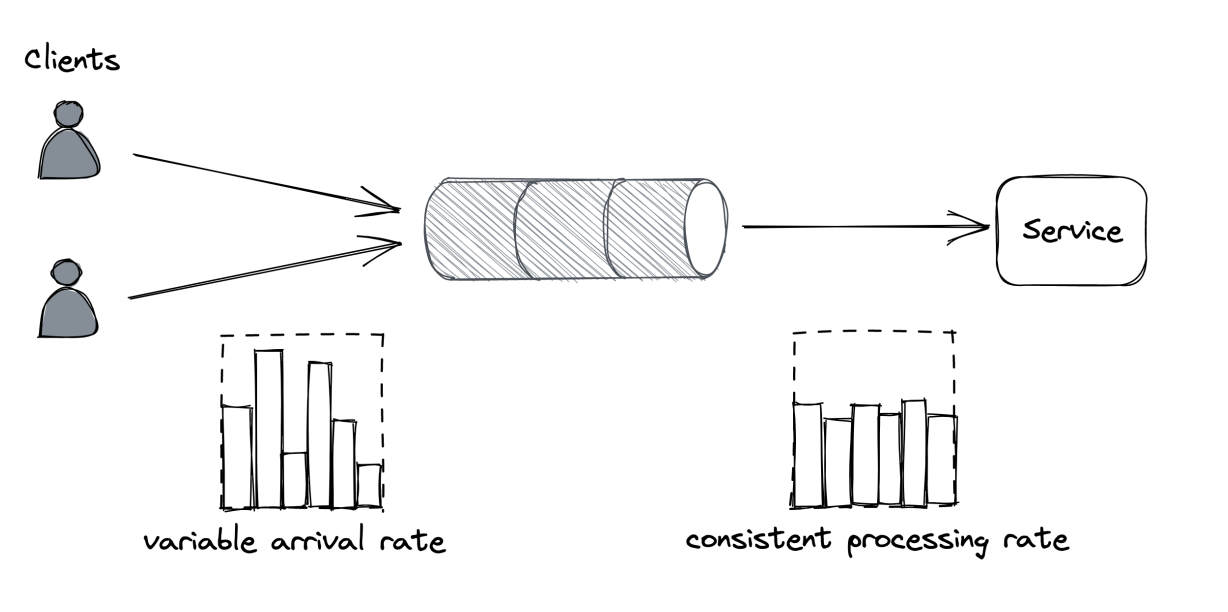
Load-shedding and load leveling don’t address an increase in load directly but rather protect a service from getting overloaded. To handle more load, the service needs to be scaled out. This is why these protection mechanisms are typically combined with auto-scaling, which detects that the service is running hot and automatically increases its scale to handle the additional load.
Rate-limiting
Rate-limiting, or throttling, is a mechanism that rejects a request when a specific quota is exceeded. A service can have multiple quotas, e.g., for the number of requests or bytes received within a time interval. Quotas are typically applied to specific users, API keys, or IP addresses.
For example, if a service with a quota of 10 requests per second per API key receives on average 12 requests per second from a specific API key, it will, on average, reject 2 requests per second from that API key.
When a service rate-limits a request, it needs to return a response with a particular error code so that the sender knows that it failed because a quota has been exhausted. For services with HTTP APIs, the most common way to do that is by returning a response with status code 429 (Too Many Requests). The response should include additional details about which quota has been exhausted and by how much; it can also include a Retry-After header indicating how long to wait before making a new request:
If the client application plays by the rules, it will stop hammering the service for some time, shielding the service from non-malicious users monopolizing it by mistake. In addition, this protects against bugs in the clients that cause a client to hit a downstream service for one reason or another repeatedly.
Rate-limiting is also used to enforce pricing tiers; if users want to use more resources, they should also be willing to pay more. This is how you can offload your service’s cost to your users: have them pay proportionally to their usage and enforce pricing tiers with quotas.
You would think that rate-limiting also offers strong protection against a DDoS attack, but it only partially protects a service from it. Nothing forbids throttled clients from continuing to hammer a service after getting 429s. Rate-limited requests aren’t free either — for example, to rate-limit a request by API key, the service has to pay the price of opening a TLS connection, and at the very least, download part of the request to read the key. Although rate limiting doesn’t fully protect against DDoS attacks, it does help reduce their impact.
Economies of scale are the only true protection against DDoS attacks. If you run multiple services behind one large gateway service, no matter which of the services behind it are attacked, the gateway service will be able to withstand the attack by rejecting the traffic upstream. The beauty of this approach is that the cost of running the gateway is amortized across all the services that are using it.
Although rate-limiting has some similarities with load shedding, they are different concepts. Load shedding rejects traffic based on the local state of a process, like the number of requests concurrently processed by it; rate-limiting instead sheds traffic based on the global state of the system, like the total number of requests concurrently processed for a specific API key across all service instances. And because there is a global state involved, some form of coordination is required.
Single-process rate limiting implementation
The distributed implementation of rate-limiting is interesting in its own right, and it’s well worth spending some time discussing it. We will start with a single-process implementation first and then extend it to a distributed one.
Suppose we want to enforce a quota of 2 requests per minute, per API key. A naive approach would be to use a doubly-linked list per API key, where each list stores the timestamps of the last N requests received. Whenever a new request comes in, an entry is appended to the list with its corresponding timestamp. Then, periodically, entries older than a minute are purged from the list.
By keeping track of the list’s length, the process can rate-limit incoming requests by comparing it with the quota. The problem with this approach is that it requires a list per API key, which quickly becomes expensive in terms of memory as it grows with the number of requests received.
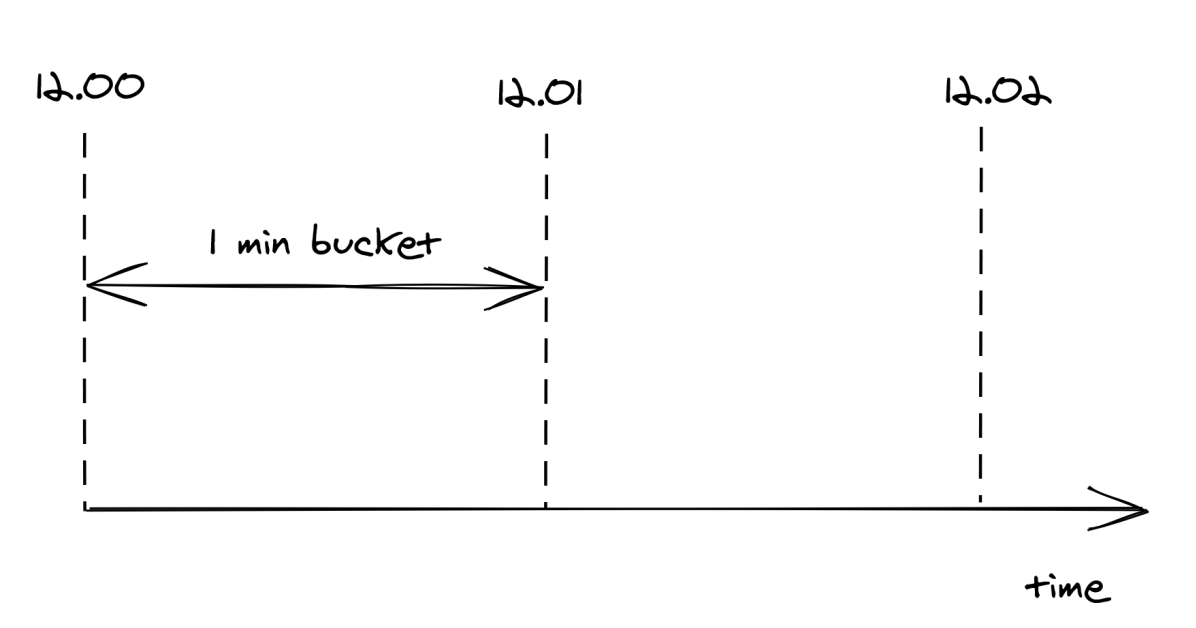
To reduce memory consumption, we need to come up with a way to reduce the storage requirements. One way to do this is by dividing time into buckets of fixed duration, for example of 1 minute, and keeping track of how many requests have been seen within each bucket (see Figure 28.2).
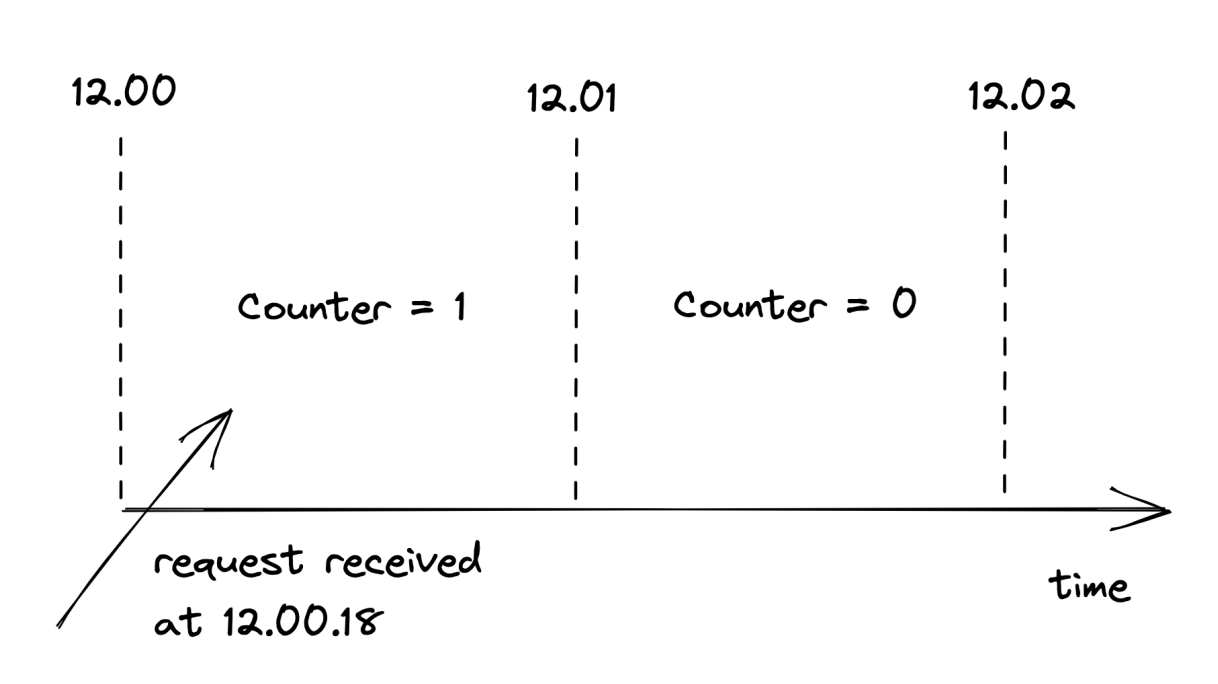
A bucket contains a numerical counter. When a new request comes in, its timestamp is used to determine the bucket it belongs to. For example, if a request arrives at 12.00.18, the counter of the bucket for minute “12.00” is incremented by 1 (see Figure 28.3).
With bucketing, we can compress the information about the number of requests seen in a way that doesn’t grow with the number of requests. Now that we have a memory-friendly representation, how can we use it to implement rate-limiting? The idea is to use a sliding window that moves across the buckets in real time, keeping track of the number of requests within it.
The sliding window represents the interval of time used to decide whether to rate-limit or not. The window’s length depends on the time unit used to define the quota, which in our case is 1 minute. But there is a caveat: a sliding window can overlap with multiple buckets. To derive the number of requests under the sliding window, we have to compute a weighted sum of the bucket’s counters, where each bucket’s weight is proportional to its overlap with the sliding window (see Figure 28.4).
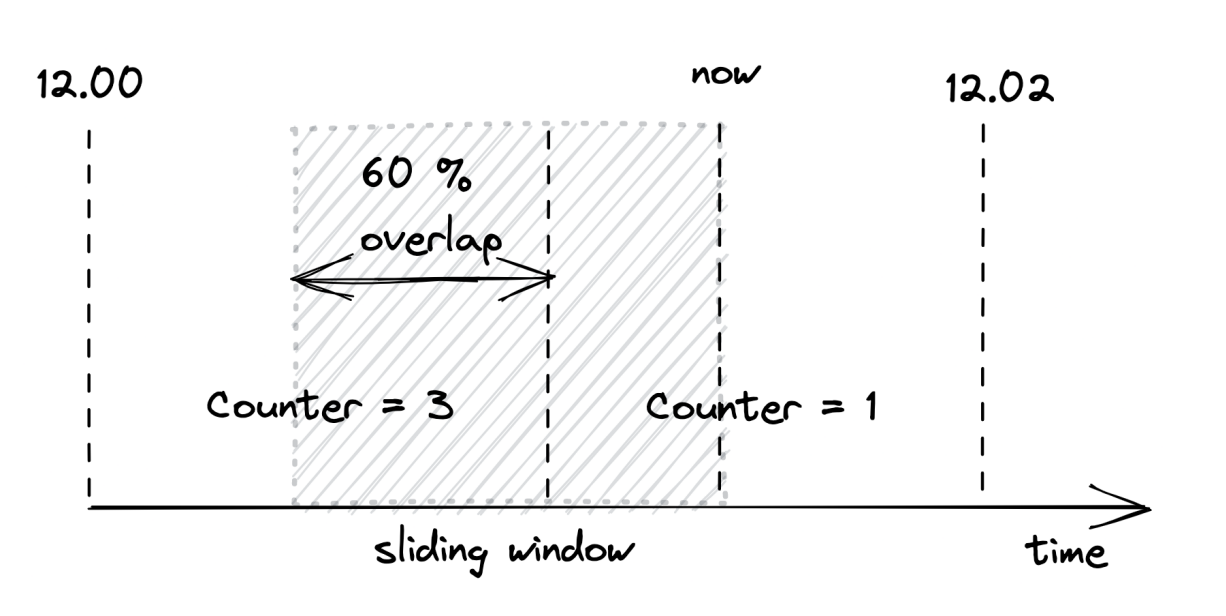
Although this is an approximation, it’s a reasonably good one for our purposes. And it can be made more accurate by increasing the granularity of the buckets. So, for example, we can reduce the approximation error using 30-second buckets rather than 1-minute ones.
We only have to store as many buckets as the sliding window can overlap with at any given time. For example, with a 1-minute window and a 1-minute bucket length, the sliding window can overlap with at most 2 buckets. Thus, there is no point in storing the third oldest bucket, the fourth oldest one, etc.
To summarize, this approach requires two counters per API key, which is much more efficient in terms of memory than the naive implementation storing a list of requests per API key.
Distributed rate limiting implementation
When more than one process accepts requests, the local state is no longer good enough, as the quota needs to be enforced on the total number of requests per API key across all service instances. This requires a shared data store to keep track of the number of requests seen.
As discussed earlier, we need to store two integers per API key, one for each bucket. When a new request comes in, the process receiving it could fetch the current bucket, update it and write it back to the data store. But that wouldn’t work because two processes could update the same bucket concurrently, which would result in a lost update. The fetch, update, and write operations need to be packaged into a single transaction to avoid any race conditions.
Although this approach is functionally correct, it’s costly. There are two issues here: transactions are slow, and executing one per request would be very expensive as the data store would have to scale linearly with the number of requests. Also, because the data store is a hard dependency, the service will become unavailable if it can’t reach it.
Let’s address these issues. Rather than using transactions, we can use a single atomic get-and-increment operation that most data stores provide. Alternatively, the same can be emulated with a compare-and-swap. These atomic operations have much better performance than transactions.
Now, rather than updating the data store on each request, the process can batch bucket updates in memory for some time and flush them asynchronously to the data store at the end of it (see Figure 28.5). This reduces the shared state’s accuracy, but it’s a good trade-off as it reduces the load on the data store and the number of requests sent to it.
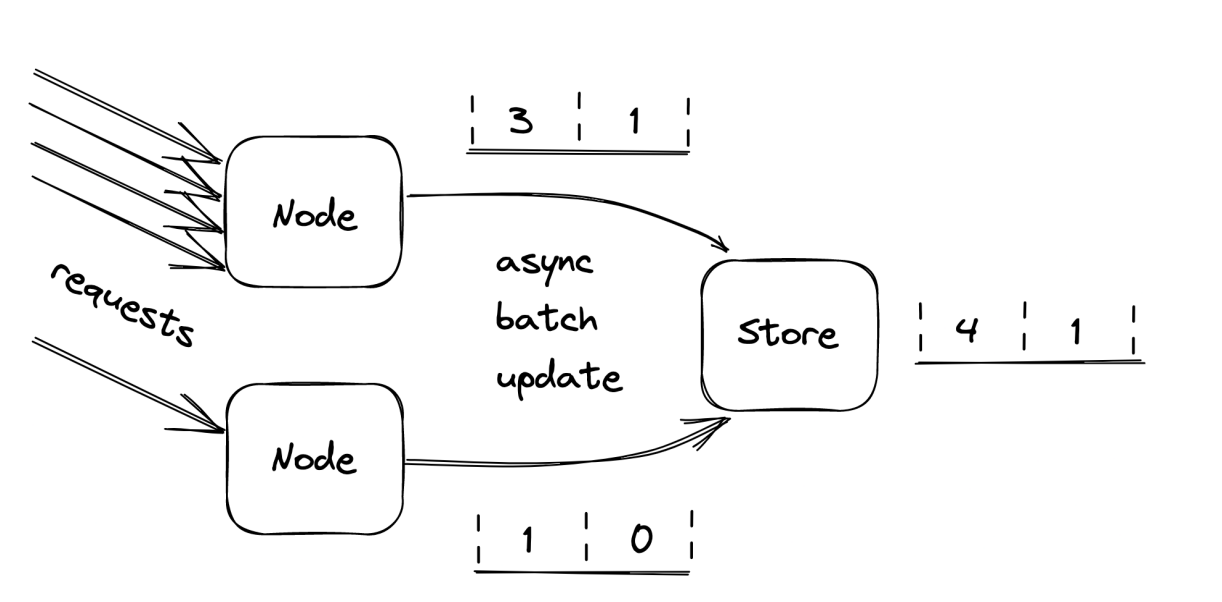
What happens if the data store is down? Remember the CAP theorem’s essence: when there is a network fault, we can either sacrifice consistency and keep our system up or maintain consistency and stop serving requests. In our case, temporarily rejecting requests just because the data store used for rate-limiting is not reachable could damage the business. Instead, it’s safer to keep serving requests based on the last state read from the store.
Constant work
When overload, configuration changes, or faults force an application to behave differently from usual, we say the application has a multi-modal behavior. Some of these modes might trigger rare bugs, conflict with mechanisms that assume the happy path, and more generally make life harder for operators, since their mental model of how the application behaves is no longer valid. Thus, as a general rule of thumb, we should strive to minimize the number of modes.
For example, simple key-value stores are favored over relational databases in data planes because they tend to have predictable performance. A relational database has many operational modes due to hidden optimizations, which can change how specific queries perform from one execution to another. Instead, dumb key-value stores behave predictably for a given query, which guarantees that there won’t be any surprises.
A common reason for a system to change behavior is overload, which can cause the system to become slower and degrade at the worst possible time. Ideally, the worst- and average-case behavior shouldn’t differ. One way to achieve that is by exploiting the constant work pattern, which keeps the work per unit time constant.
The idea is to have the system perform the same amount of work under high load as under average load. And, if there is any variation under stress, it should be because the system is performing better, not worse. Such a system is also said to be antifragile. This is a different property from resiliency; a resilient system keeps operating under extreme load, while an antifragile one performs better.
We have already seen one application of the constant work pattern when discussing the propagation of configuration changes from the control plane to the data plane in chapter 22. For example, suppose we have a configuration store (control plane) that stores a bag of settings for each user, like the quotas used by the API gateway (data plane) to rate-limit requests. When a setting changes for a specific user, the control plane needs to broadcast it to the data plane. However, as each change is a separate independent unit of work, the data plane needs to perform work proportional to the number of changes.
If you don’t see how this could be a problem, imagine that a large number of settings are updated for the majority of users at the same time (e.g., quotas changed due to a business decision). This could cause an unexpectedly large number of individual update messages to be sent to every data plane instance, which could struggle to handle them.
The workaround to this problem is simple but powerful. The control plane can periodically dump the settings of all users to a file in a scalable and highly available file store like Azure Storage or AWS S3. The dump includes the configuration settings of all users, even the ones for which there were no changes. Data plane instances can then periodically read the dump in bulk and refresh their local view of the system’s configuration. Thus, no matter how many settings change, the control plane periodically writes a file to the data store, and the data plane periodically reads it.
We can take this pattern to the extreme and pre-allocate empty configuration slots for the maximum number of supported users. This guarantees that as the number of users grows, the work required to propagate changes remains stable. Additionally, doing so allows to stress-test the system and understand its behavior, knowing that it will behave the same under all circumstances. Although this limits the number of users, a limit exists regardless of whether the constant work pattern is used or not. This approach is typically used in cellular architectures (see 26.2), where a single cell has a well-defined maximum size and the system is scaled out by creating new cells.
The beauty of using the constant work pattern is that the data plane periodically performs the same amount of work in bulk, no matter how many configuration settings have changed. This makes updating settings reliable and predictable. Also, periodically writing and reading a large file is much simpler to implement correctly than a complex mechanism that only sends what changed.
Another advantage of this approach is that it’s robust against a whole variety of faults thanks to its self-healing properties. If the configuration dump gets corrupted for whatever reason, no harm is done since the next update will fix it. And if a faulty update was pushed to all users by mistake, reverting it is as simple as creating a new dump and waiting it out. In contrast, the solution that sends individual updates is much harder to implement correctly, as the data plane needs complex logic to handle and heal from corrupted updates.
To sum up, performing constant work is more expensive than doing just the necessary work. Still, it’s often worth considering it, given the increase in reliability and reduction in complexity it enables.
These were chapters 27 and 28 from the book Understanding Distributed Systems by Roberto Vitillo. To dive deeper, get the e-book from the Understanding Distributed Systems website, or the print book off Amazon. You can also follow Roberto on Twitter and connect with him on LinkedIn.
Subscribe to my weekly newsletter to get articles like this in your inbox. It's a pretty good read - and the #1 software engineering newsletter on Substack.