Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover Big Tech and startups through the lens of senior engineers and engineering leaders. Today, we cover one out of four topics from last week’s The Pulse issue. Full subscribers received the article below eight days ago. If you’ve been forwarded this email, you can subscribe here.
We’re used to highly reliable systems which target four-nines of availability (99.99%, meaning about 52 minutes of downtime per year), and for it to be embarrassing to barely hit three nines (around 9 hours of downtime per year.) And yet, in the past month, GitHub’s reliability is down to one nine!
Here’s data from the third-party, “missing GitHub status page”, which was built after GitHub stopped updating its own status page due to terrible availability. Recently, things have looked poor:
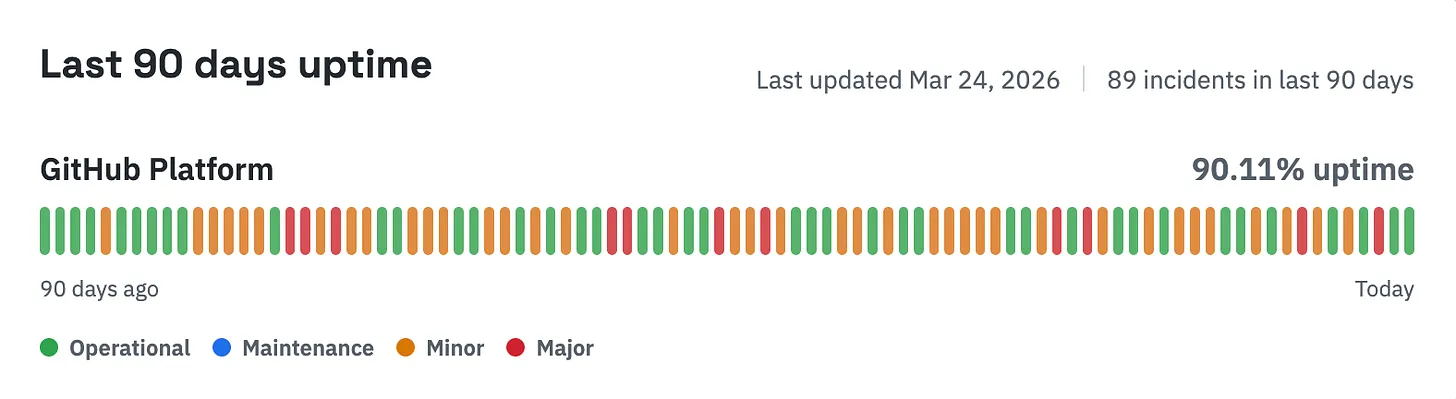
This means that for every 30 days, GitHub had issues on 3 days, or issues/degradations for 2.5 hours daily (around 10% of the time.)
GitHub seems unable to keep up with the massive increase in infra load from agents. One software engineer built a clever website called “Claude’s Code” that tracks Claude Code bot contributions across GitHub. Growth in the past three months has been enormous:
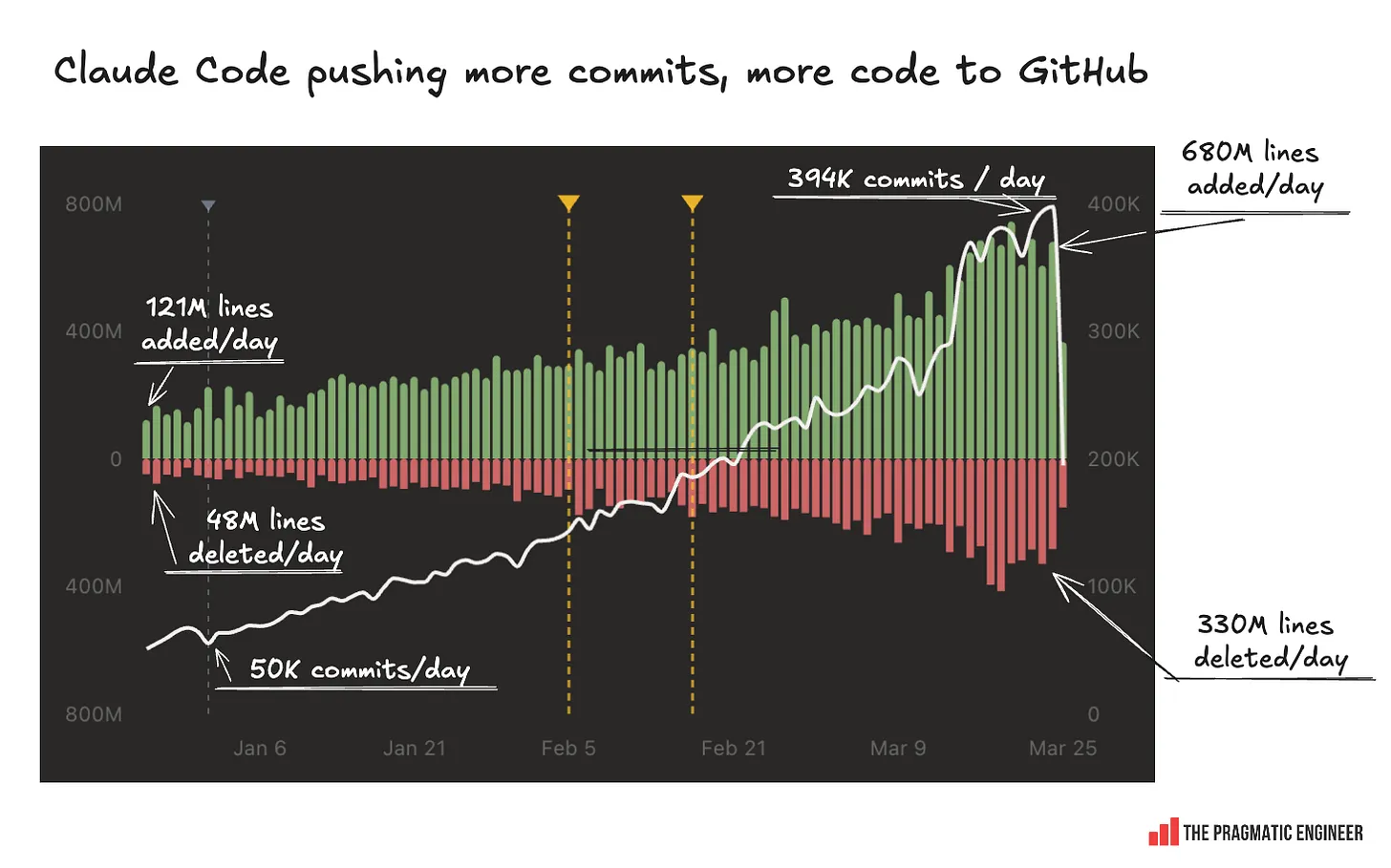
Stream of GitHub outages from infra overload
GitHub’s CTO, Vladimir Fedorov, addressed availability issues in a blog post and covered three major incidents:
- 2 February: security policies unintentionally blocked access to virtual machine metadata
- 9 February: a database cluster got overloaded
- 5 March: writes failed on a Redis cluster
Software engineer Lori Hochstein did a helpful analysis of these outages and the CTO’s response, and has interesting observations:
- Saturation: the database cluster incident (9 Feb) was a case of the database getting saturated, due to higher-than-expected usage. Databases are harder to scale up than stateless services. GitHub also underestimated how much additional traffic there would be.
- Failover + telemetry gap: the 2 Feb incident was a combination of an infra issue in one region failing over to a healthy region, and making things worse with a telemetry gap (incorrect security policies were applied in the new regions which blocked access to VM metadata)
- Failover + configuration issue: the 5 March incident was uncannily similar: after a failover, a configuration issue blocked writes on a Redis cluster
It is certainly nice to get details from GitHub on these outages. It feels to me that infra strains are causing more infra issues → they trigger constraints faster → failovers are not as smooth as they should be. Could it be because GitHub keeps changing their existing systems?
Startup shows GitHub how it’s done
While GitHub struggles to keep up with the increase in load from AI agents generating more code and pull requests, a new startup called Pierre Computer claims to have built an “AI-native” solution for AI agents pushing code, which scales far beyond what GitHub can do. Pierre was founded by Jacob Thornton: formerly an engineer at Coinbase, Medium, and Twitter, and also the creator of the once-very popular Bootstrap CSS library.
Here’s what Pierre supports, which GitHub does not:
“In October [2025], Github shared they were averaging ~230 new repos per minute.
Last week we [at Pierre Computer] hit a sustained peak of > 15,000 repos per minute for 3 hours.
And in the last 30 days customers have created > 9M repos”
These are incredible numbers – if also self-reported – and something that GitHub clearly cannot get close to, at least not today! There are few details about customers, while the product – called Code.storage – seems to be in closed beta.
Still, this is the type of “git for AI agents” that GitHub has failed to build, and the type of infrastructure it needs badly.
Has GitHub lost focus and purpose?
GitHub’s reliability issues are acute enough that, if it keeps up, teams will start giving alternatives like small startups such as Pierre a try, or perhaps even consider self-hosting Git. But how did the largest Git host in the world neglect its customers, and fail to prepare its infra for an increase in code commits and pull requests?
Mitchell Hashimoto, founder of Ghostty, and a heavy user of GitHub himself, had advice on what he would do if he was in charge of GitHub, after growing frustrated with the state of its core offering. He writes (emphasis mine)
“Here’s what I’d do if I was in charge of GitHub, in order:
1. Establish a North Star plan around being critical infrastructure for agentic code lifecycles and determine a set of ways to measure that.
2. Fire everyone who works on or advocates for Copilot and shut it down. It’s not about the people, I’m sure there’s many talented people; you’re just working at the wrong company.
3. Buy Pierre and launch agentic repo hosting as the first agentic product. Repos would be separate from the legacy web product to start, since they’re likely burdened with legacy cross product interactions.
4. Re-evaluate all product lines and initiatives against the new North Star. I suspect 50% get cut (to make room for different ones).
The big idea is all agentic interactions should critically rely on GitHub APIs. Code review should be agentic but the labs should be building that into GH (not bolted in through GHA like today, real first class platform primitives). GH should absolutely launch an agent chat primitive, agent mailboxes are obviously good. GH should be a platform and not an agent itself.
This is going to be very obviously lacking since I only have external ideas to work off of and have no idea how GitHub internals are working, what their KPIs are or what North Star they define, etc.
But, with imperfect information, this is what I’d do.”
My sense is that GitHub has three concurrent problems:
- GitHub and Copilot are entangled with Microsoft’s internal politics. GitHub’s Copilot in 2021 was the first massively successful “AI product.” Microsoft took the “Copilot” brand and used it across all of their product lines, creating low-quality AI integrations. Simultaneously, internal Microsoft orgs like Azure and Microsoft AI were trying to get their hands on GitHub, which is one of the most positive developer brands at Microsoft.
- GitHub has no leader, seemingly by design. GitHub’s last CEO was Thomas Dohmke, who stepped down voluntarily, and Microsoft never backfilled the CEO role; instead carrying out a reorg to make GitHub part of Microsoft’s AI group and stripping its independence. It seems the “Microsoft AI” side won that battle.
- GitHub has no focus, and is stuck chasing Copilot as a revenue source. GitHub has no CEO and is caught up in internal politics, so, what can GitHub teams do? The safest bet is to increase revenue and the best way to do that is by investing more into GitHub Copilot, and ignoring long-term issues like reliability.
I agree with Mitchell: GitHub has no “North Star” and we see a large org being dysfunctional. That lack of vision – and CEO – is hitting hard:
- GitHub Copilot went from the most-used AI agent in 2021, to be overtaken by Claude Code, and is soon to be overtaken by Cursor.
- As a platform, GitHub has no vision for how to evolve to support AI agents. Sure, GitHub has an MCP server, but it has no “AI-native git platform” that can handle the massive load AI agents generate.
- GitHub keeps shipping small features and improvements without direction. For example, in October 2025, they started to work on stacked diffs. However, when it ships, the stacked diffs workflow might be mostly obsolete – at least with AI agents!
It’s easy to win a market when you do one thing better than anyone else in the world. Right now, GitHub is doing too many things and doing a subpar job with Copilot, its platform, and AI infra.
Read the full issue of last week’s The Pulse, or check out this week’s The Pulse.
Catch up with recent The Pragmatic Engineer issues:
- Scaling Uber with Thuan Pham (Uber’s first CTO — podcast). We went into topics like scaling Uber from constant outages to global infrastructure, the shift to microservices and platform teams, and how AI is reshaping engineering.
- Building WhatsApp with Jean Lee (podcast): Jean Lee, engineer #19 at WhatsApp, on scaling the app with a tiny team, the Facebook acquisition, and what it reveals about the future of engineering.
- What will the Staff Engineer role look like in 2027 and beyond? What happens to the Staff engineer role when agents write more code? Actually, they could be more in demand than ever!
Subscribe to my weekly newsletter to get articles like this in your inbox. It's a pretty good read - and the #1 tech newsletter on Substack.