Migrations Done Well: Typical Migration Approaches
This article is an excerpt from Migrations Done Well: a guide for executing migrations well, at both small and large scales, published in The Pragmatic Engineer. To get deep dives in your inbox like this issue, sign up here.
Migrations are one of the most overlooked topics in software engineering, especially at high-growth startups and companies. As a company’s operations grow, new systems and approaches are adopted to cope with extra load, more use cases, or more constraints. From time to time, engineers need to migrate over from an old system or approach, to a new one.
And this is where things can get interesting, unexpected… and even ugly.
1. The story of four different migrations
Each migration is a story in itself, so here are four migrations. Each is distinctly different from the others.
The migration with planned downtime
In 2012, PayPal announced it would take all of its global payments processing systems down for an hour, within a three-hour window. This was to be while it moved over to a new infrastructure. It was decided that taking the system down, moving data over to the new infrastructure and then spinning it up, was the safest way to go.
Even though the scheduled time was at night in the US, this migration caused losses thanks to transactions by global customers not being processed during this time. However, the migration did complete as planned, while the disruption and losses to the business were within the realm of what PayPal had planned for.
The migration gone terribly wrong
UK bank TSB has 5 million customers. It performed an IT migration in 2018, which ended up locking close to 2 million customers out of their accounts, unable to withdraw cash. Fixing the issues of the migration took many months; five months after the migration went wrong, some customers were still locked out of their account, and the CEO of the bank was forced to quit over the episode, after seven years in post.
Although the root causes are still opaque, it seems this disaster was down to a lack of proper testing ahead of the migration. Press covering the incident mentioned configuration problems, lack of infrastructure capacity and coding issues, all contributing to the problem. The outage cost the bank at least $480M in costs, not to mention heavy reputational and business damage.
The zero downtime migration
When I joined Uber in 2016, the company had two payment systems: one processing pay-ins from customers (Riders and Eaters) and one dealing with payouts for partners (Drivers and Couriers). We started building a new, single payment system to replace these two standalone systems. In 2017, we switched over to the new system – codenamed Gulfstream – to handle Uber’s payments.
The switch to a new payments system was invisible from the outside and the migration was done without downtime or major issues. This was a case of a zero downtime migration executed well.
However, the long tail of the migration stretched on for years, and this long tail later turned out to cause problems.
The migration long-tail causing an outage
Although the new payments system worked as the primary system, Uber still had dozens of internal systems that were dependent on the old payments infrastructure. The new system did writebacks to these old systems to support consumers that had not yet migrated over.
Long migrations can be risky and this case was no different. In 2018, drivers were unable to use Instant Pay for several days. The reason was an outage in the writeback system which pushed production data to the legacy system. The system which handled driver payouts still used this old system, and as writebacks were not arriving, this caused problems with payouts.
The engineering team didn’t immediately detect the outage because while the production payments system had robust monitoring, the writeback system – meant to be in place for months and not years – did not have sophisticated monitoring and alerting.
Migration long-tails are common, risky and often cause outages, just like they did in this case.
2. Types of migrations
The word ‘migration’ describes a broad range of activities. Here are the most common types of migrations we engineers come across.
Service replacement. Replace OldService with NewService and move all customers over to eventually use NewService. An example is replacing an old, legacy payments system with a new one like Uber did, in the example above.
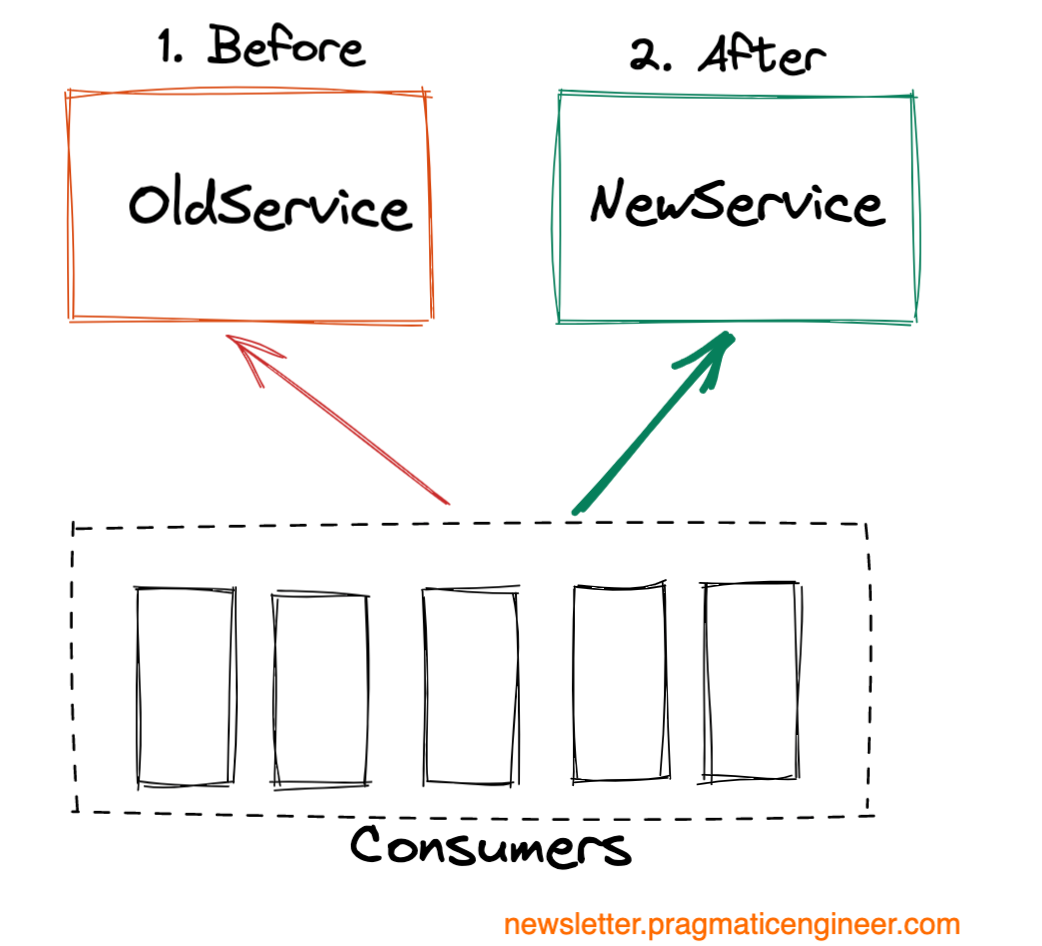
This type of migration is very common at any fast-growing company. There might be many reasons to write a new service instead of improving the old service, such as:
- The old system not supporting enough business requirements.
- The need to improve nonfunctional characteristics like handling extra load, achieving lower latency, storing more data.
- The language or framework the old service was written in, is no longer supported or preferred within the organization.
Service integration. Integrate a new service or approach.
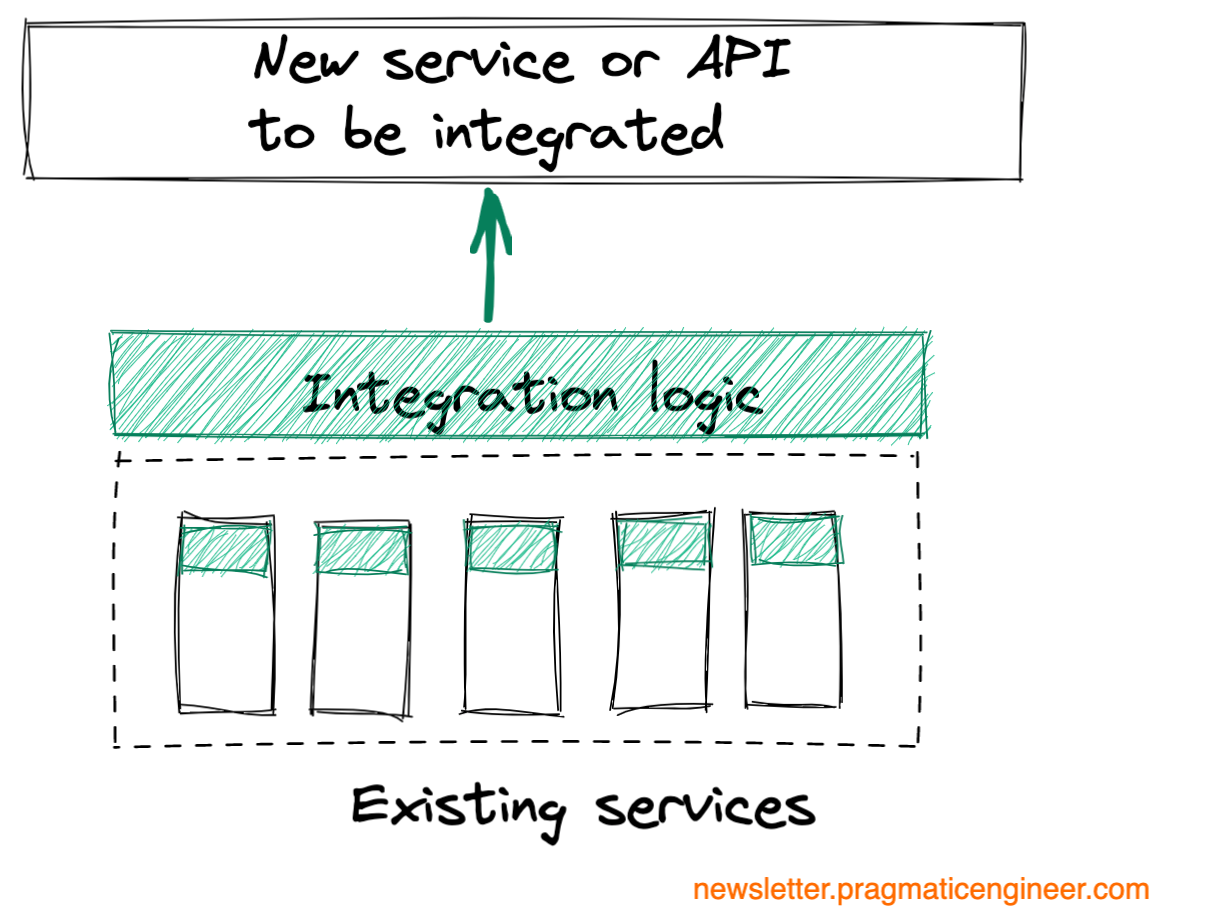
Examples include:
- Integrate a new API for use. For example, integrate a new payments processing service.
- Migrate to a new version of an external service. For example, move from the v1 API of a provider to a v2 API.
- Migrate to a new version of a service where instead of polling for events, the new service pushes events. Or instead of synchronously consuming inbound events, inbound events are consumed asynchronously, triggering callbacks.
As the examples above show, service integration migrations can include many things. There are engineers who might not even consider some of the above to be migrations, but treat them as a change in functionality. But I argue that we should treat them as migrations.
This is because these are changes where an external service alters, and your code also changes to ensure correct future behavior. This characteristic is what makes them risky changes, and why it’s wise to proceed with caution, following a migration playbook.
Service extraction. Move from an in-system dependency to an external one. This is a common approach at high-growth startups when large services get split up into smaller ones.
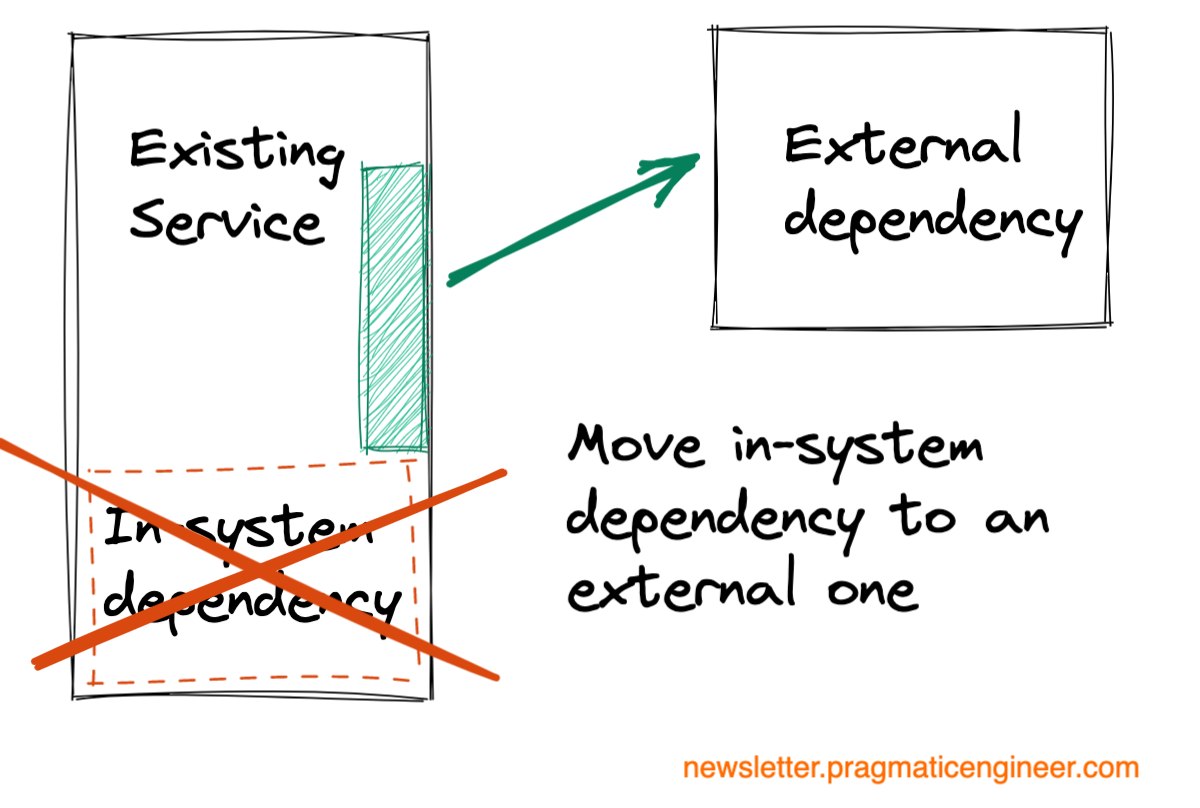
On the surface, service extractions seem like some of the most simple migrations. After all, we’re just moving code that already works into a new service, right?
Wrong.
Service extractions are much more risky than simply moving code around. There are risks around networking and the correctness of the new service; especially as the code is rarely copied and pasted. Also, extracting a service comes loaded with future operational risks.
While service extractions are one of the easiest types of migrations to pull off successfully without any monitoring or alerting in place, I suggest to avoid this temptation and to follow a more thorough migration runbook, like that we discuss below.
Code migrations. Moving a part of the codebase to use a different framework, library or a programming language.
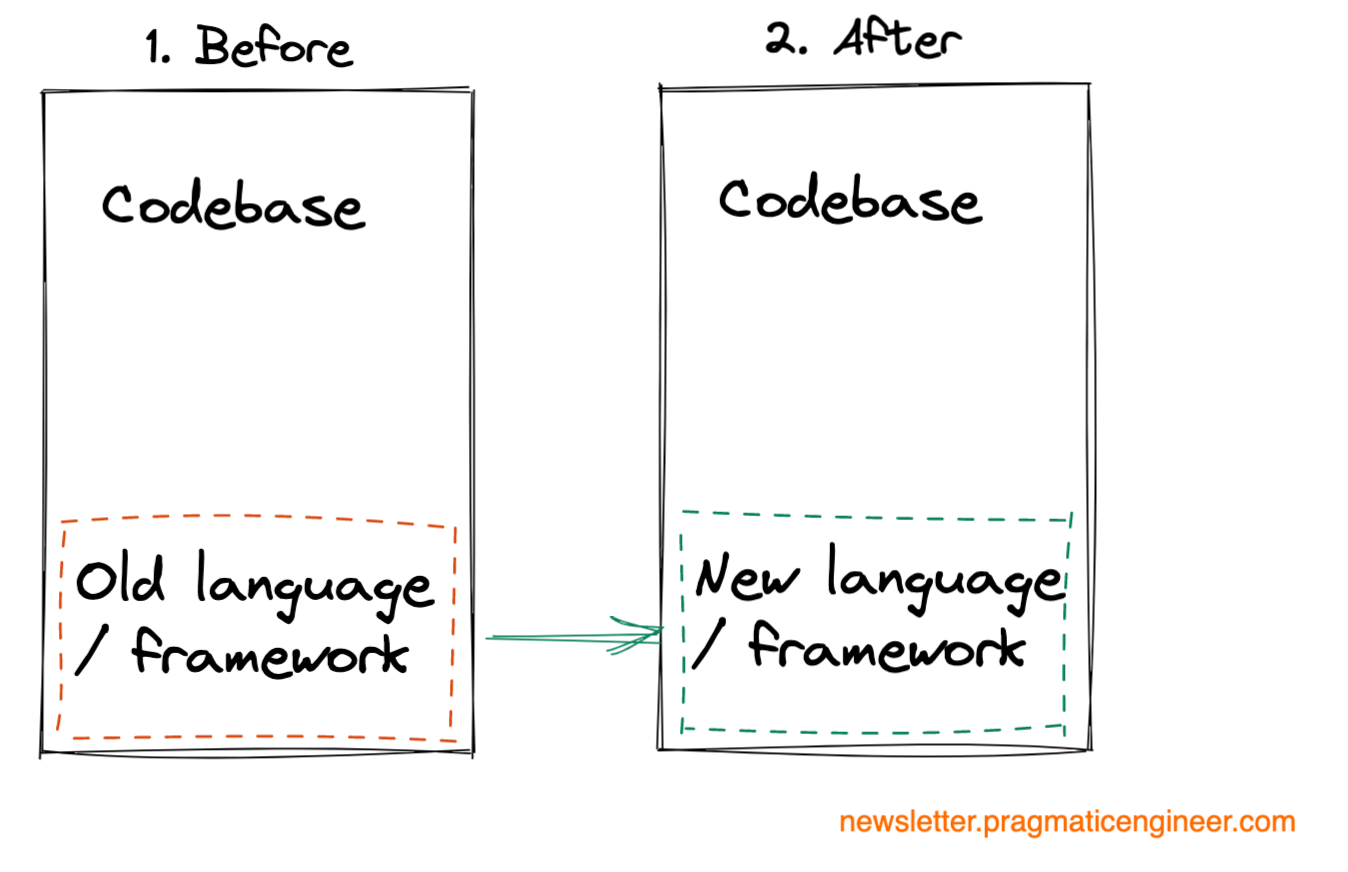
The biggest challenges of this type of migration are:
- Large-scale change. It’s not uncommon to have to change a very high number of files and lines of code.
- Hard to rollback. Because the change is so large, it’s also difficult, or sometimes impossible, to easily roll back the change. This is the opposite of most code changes which are small and can be unwound very easily.
- Harder to test in production. As the change is large-scale, it can be harder to test the full change under production traffic.
A few examples of code migrations:
- Migrating to a new language. For example, Stripe migrated 3.5M lines of code over a weekend, from JavaScript type checked by Flow to Typescript.
- Upgrading to a new major version of a library, which introduces API-breaking changes.
- Changing coding patterns across the codebase. For example, updating a JavaScript codebase codebase to use promises instead of callbacks.
Data migrations. Migrating one or more databases to a new schema or database engine.
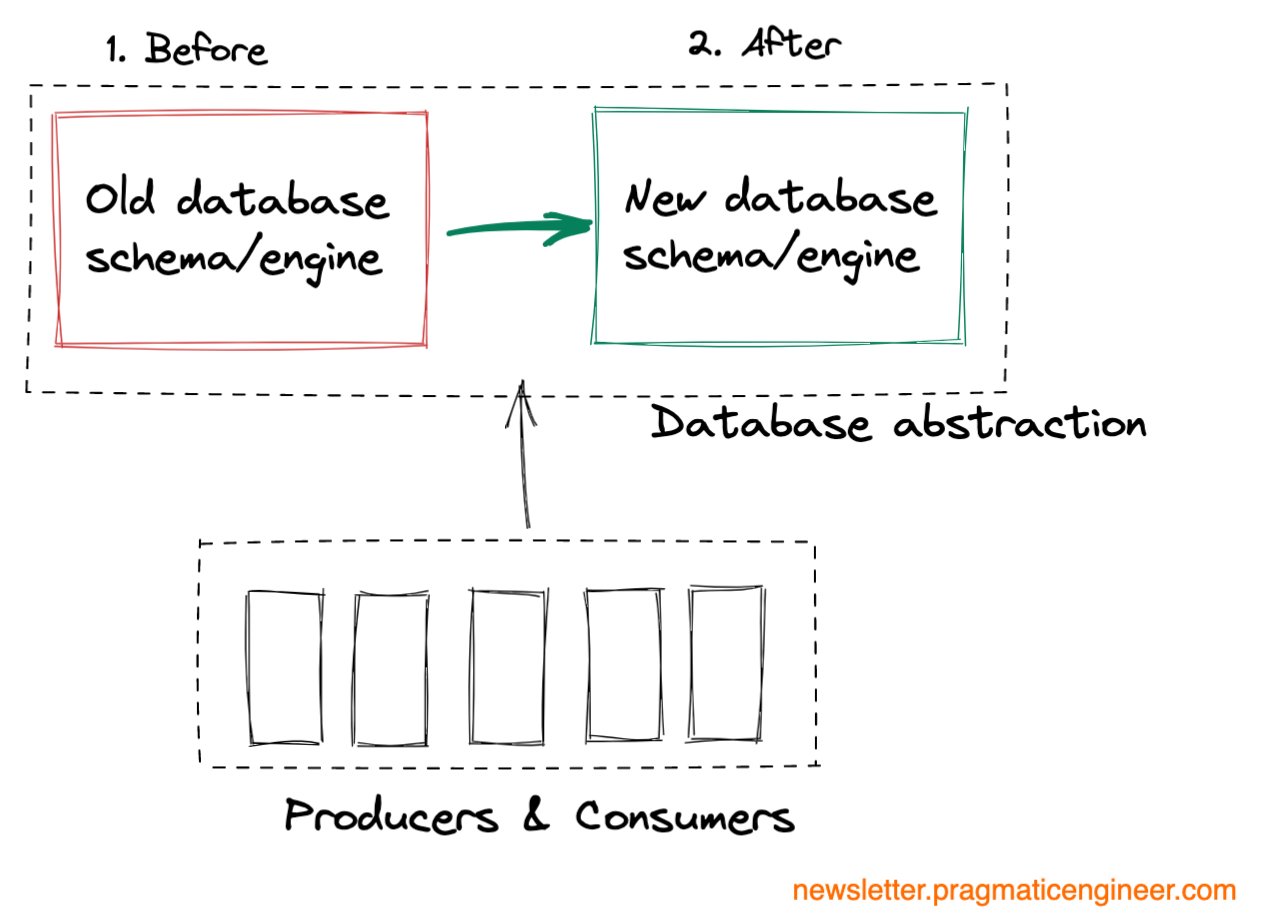
Data migrations are one of the most risky types of migrations. There are several reasons why:
- Difficult to roll back. When code is changed, it’s easy enough to roll back a migration by rolling back the code. But this isn’t always the case with data.
- Difficult to do in an atomic way. Ideally, a data migration is done as an atomic step. From one moment to the next, the old database or schema stops being used and all data moves to the new database or schema. But in practice, moving data takes time. This is why it’s much easier to do a data migration with downtime.
- Data migration is often tied to code changes. For the migration to work as expected, code changes often need to be made at the very same time as the data is migrated.
- More edge cases to worry about. You will need to worry about edge cases like producers writing to the old database or using the old schema, or consumers not being able to understand the new schema.
Infrastructure migrations. Move storage, computing or networking infrastructure to a new provider or a new location.
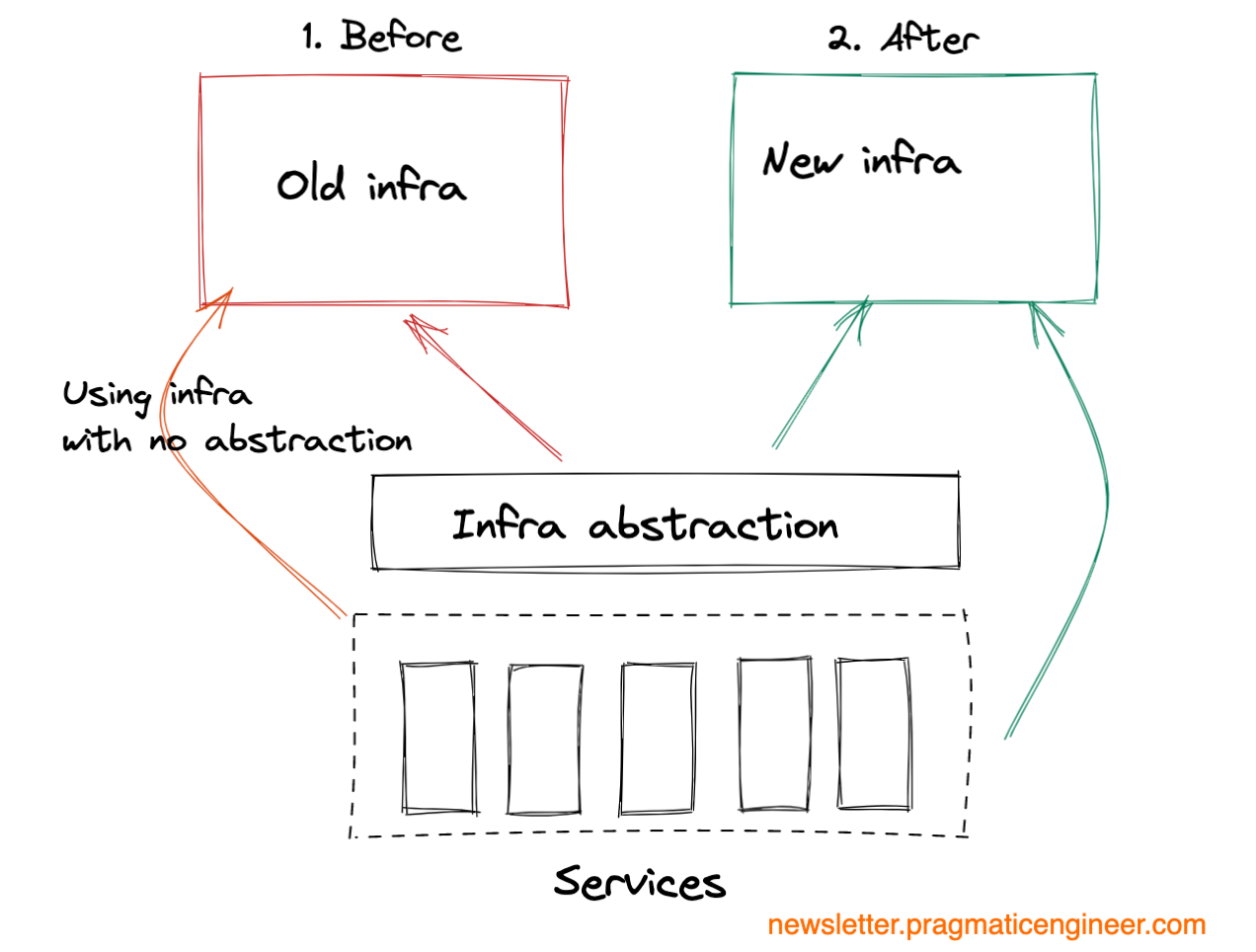
Infrastructure migrations are the most risky, as they impact all services using that infrastructure. An infrastructure migration gone wrong can take down all dependent services with it. For this reason, these are the ones that typically need more preparation than even data migrations.
While all other migrations are virtual in the sense that they typically involve moving code or data, infrastructure migrations are when the physical infrastructure might also need to be moved or changed, and onsite work might be needed. Although most companies use cloud computing providers like AWS, Azure or Google Cloud, plenty of companies still operate their own data centers, or run their own server boxes. Infrastructure migrations can mean changes to these as well.
Service and tool upgrades are also changes which can cause outages. Examples of this include upgrading the CI/CD system to the latest version, updating JIRA to a new version, and other tooling infrastructure changes.
But for upgrades, the vendor of the tool is the one performing the migration. It’s advisable to understand how this migration happens under the hood and if it’s a high-risk upgrade, and to use the approaches in this article to reduce the risks of the update.
This was part 1 of 3 on how to do migrations well. Read the rest of the guide here: Migrations Done Well: a guide for executing migrations well, at both small and large scales.
Part 2: Executing a migration. Read it here.
- Preparation
- Pre-migration
- The migration
- After the migration
- The migration’s long-tail
Part 3: The people and the business side of migrations. Read it here.
- The people aspect of migrations
- Selling migrations to the business
- Closing advice for migrations
- Further reading
Subscribe to my weekly newsletter to get articles like this in your inbox. It's a pretty good read - and the #1 software engineering newsletter on Substack.