10 Engineering Challenges Due to the Nature of Mobile Applications
I've been noticing that while there's a lot of appreciation for backend and distributed systems challenges, there's a lot less empathy for why mobile development is hard when done at scale. Building a backend system that serves millions of parallel customers means building highly available and scalable systems and operating these reliably. But what about the mobile clients for the same systems?
I've been building native mobile apps since 2010: starting on Windows Phone, later on iOS, and Android. Starting from one person apps, I worked with small teams at Skyscanner, to hundreds of engineers working on the same codebase at Uber. Here, I've been part of the Rider app rewrite, Driver app rewrite, both projects involving hundreds of mobile engineers. The apps my team worked on had 100M monthly users in 60+ countries, with several features built for a single country or region.
Most engineers - who have not built mobile apps - assume the mobile app is a simple facade that requires less engineering effort to build and operate. Having built both types of systems: this is not the case. There is plenty of depth in building large, native, mobile applications - but often little curiosity from people not in this space. Product managers, business stakeholders, and even non-native mobile engineers rarely understand why it "takes so long" to ship something on mobile.
This series of articles collects challenges engineers face when building native iOS and Android apps at scale: scale meaning they have a large number of users, are built by large teams, launch features continuously, and need to operate reliably. It's a summary of the current industry practices used by large native mobile teams. I hope this piece helps non-mobile engineers build empathy for the type of challenges and tradeoffs mobile engineers face and be a conversation starter between backend, web and mobile teams.
39 Engineering Challenges of Building Mobile Apps at Scale: Table of Contents
This article series is the largest piece of content on my blog, by a lot. I've been writing it for over a year and 15+ mobile experts have contributed to the piece with content and reviews. The completed series turned into the book Building Mobile Apps at Scale.
Challenges due to the nature of mobile applications (this article)
- 1. State management
- 2. Mistakes are hard to revert
- 3. The long tail of old app versions
- 4. Deeplinks
- 5. Push and background notifications
- 6. App crashes
- 7. Offline support
- 8. Accessibility
- 9. CI/CD and the build train
- 10. Third-party libraries and SDKs
- 11. Device & OS fragmentation
- 12. In-App Purchases
(The below challenges are all covered in Building Mobile Apps at Scale)
Challenges due to app complexity and large dev teams
- 13. Navigation architecture within large apps
- 14. Application state & event-driven changes
- 15. Localization
- 16. Modular architecture & dependency injection
- 17. Automating testing challenges
- 18. Manual testing
Challenges due to large engineering teams
- 19. Planning and decision making
- 20. Architecting ways to avoid stepping on each other’s toes
- 21. Shared architecture across several apps
- 22. Tooling maturity for large engineering teams
- 23. Scaling build & merge times
- 24. Mobile platform libraries and teams
Languages and cross-platform approaches
- 25. Adopting new languages and frameworks
- 26. Kotlin Multiplatform and KMM
- 27. Cross-platform feature development
- 28. Cross-platform app development versus native
- 29. Web, PWA & backend-driven mobile apps
Challenges due to stepping up your game
- 30. Experimentation
- 31. Feature flag hell
- 32. Performance
- 33. Analytics, monitoring and alerting
- 34. Mobile on-call
- 35. Advanced code quality checks
- 36. Compliance, privacy and security
- 37. Client-side data migrations
- 38. Forced upgrading
- 39. App Size
When Things are Simple
Let's address the elephant in the room: the frequent assumption that client-side development is simple. The assumption that the biggest complexity lies in making sure things look good on various mobile devices.
When the problem you are solving is simple, and the scope is small, it's easier to come up with simple solutions. When you're building an app with limited functionality with a small team and very few users, your mobile app shouldn't be complicated. Your backend will likely be easy to understand. Your website will be a no-brainer. You can use existing libraries, templates, and all sorts of shortcuts to put working solutions in place.
Once you grow in size - customers, engineers, codebase, features - everything becomes more complex, more bloated, and harder to understand and modify: including the mobile codebase. This is the part we'll focus on in this article: when things have become complex. Once your app has grown, there are no silver bullets that will magically solve all of your pain points, only tough tradeoffs to make.
1. State Management
State management is the root of most headaches for native mobile development - similar to modern web and backend development. The difference with mobile apps is how app life cycle events and transitions are not a cause for concern in the web and backend world. Examples of the app-level lifecycle transitions are the app pause and going to the background, coming back to the foreground or being suspended. The states are similar, but not identical for iOS and Android.
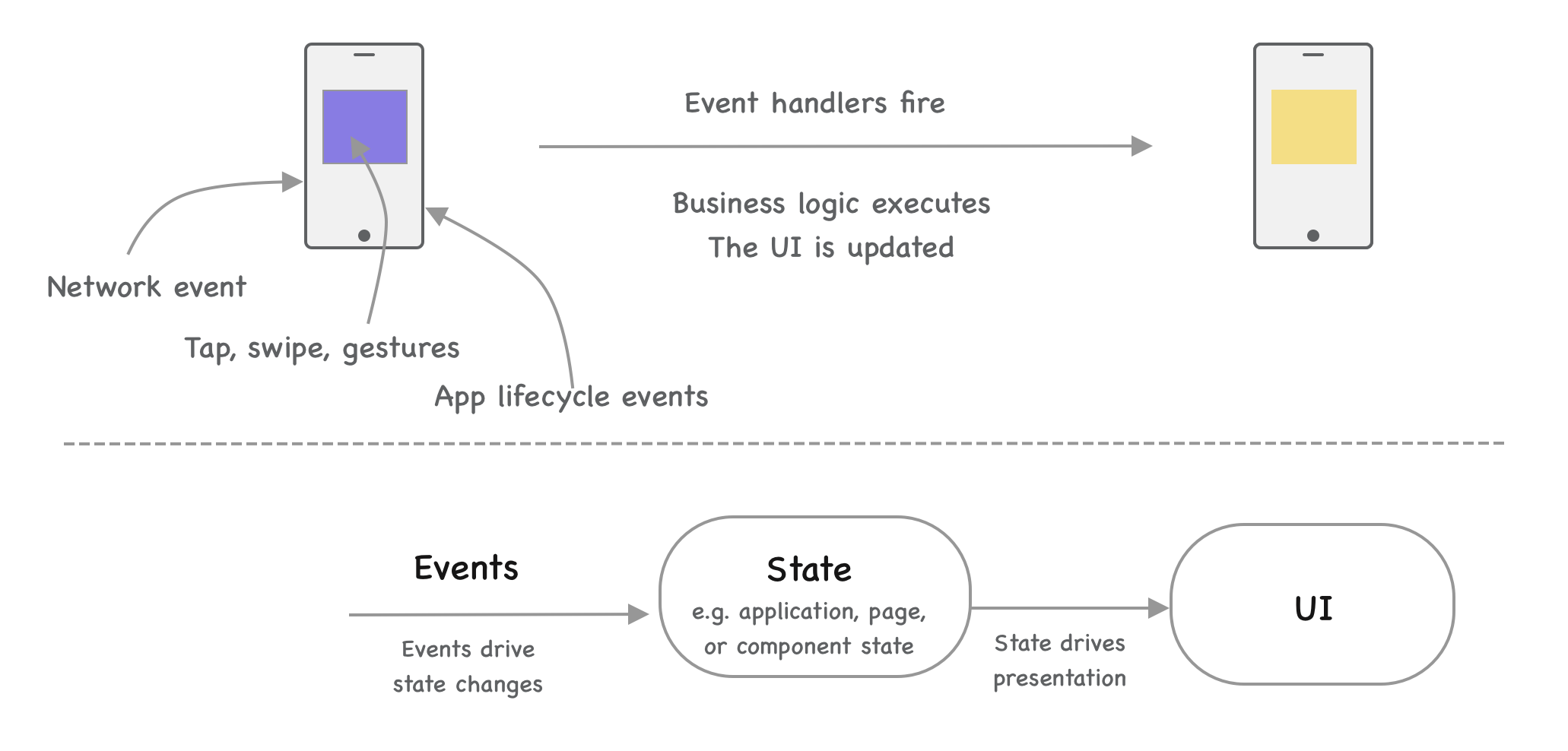
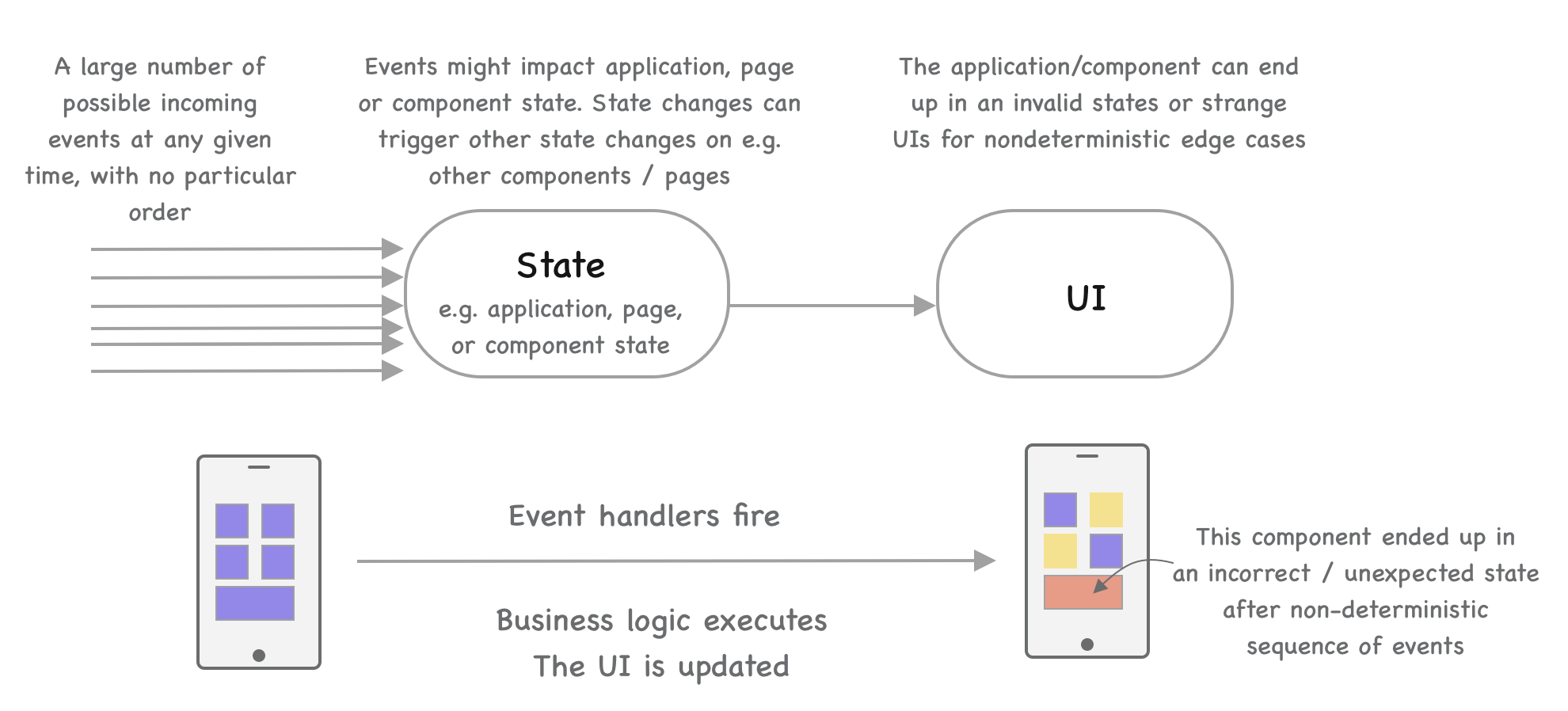
Events drive state changes in most mobile apps. These events trigger in an asynchronous way - application state changes, network requests, user input. Most bugs and unexpected crashes are usually caused by an unexpected or untested combination of events and the application's state getting corrupted. State becoming corrupted is a common problem area with apps where global or local states are manipulated by multiple components unbeknown to each other. Teams that run into this issue start to isolate component and application state as much as possible and tend to start using reactive state management sooner or later.
Reactive programming is a preferred method to deal with a large and stateful app to isolate state changes. You keep state as immutable as possible, storing models as immutable objects that emit state changes. This is the practice used at Uber, the approach Airbnb takes, or how N26 have built their app. Though the approach can be tedious in propagating state changes down a tree of components, the same tediousness makes it difficult to make unintended state changes in unrelated components.
Applications sharing the same resources with all other apps and the OS killing apps on short notice is one of the biggest differences between developing for mobile versus developing for other platforms - like backend and the web. The OS monitors CPU, memory, and energy consumption. If the OS determines that your app is taking up too many resources - may this be in the foreground or the background - then it can be killed with little warning. It is the app developer's responsibility to react to application state changes, save state, and restore the app to where it was running. On iOS, this means handling app states and transitions between them. On Android, you need to react to changes in the Activity lifecycle.
Global application state - permissions, Bluetooth and connectivity state, and others - brings an interesting set of challenges. Whenever one of these global states changes - for example, the network connectivity drops - different parts of the app might need to react differently.
With global state, the challenge becomes deciding what component owns listening to these state changes. On one end of the spectrum, application pages or components could listen to global state changes they care about - resulting in lots of code duplication, but components handling all global state concerns. On the other end, a component could listen to certain global state changes and forward these on to specific parts of the application. This might result in less complex code, but now there's a tight coupling between the global state handler and the components that it knows of.
App launch points like deeplinks or internal "shortcut" navigation within the app also add complexity to state management. With deeplinks, additional state might need to be set up after the deeplink was activated. We'll go into more detail in the Deeplinks section.
2. Mistakes Are Hard to Revert
Mobile apps are distributed as binaries. Once a user updates to a version with a client-side bug, they are stuck with that bug until a new version is released and this user updates.
Multiple challenges come from this approach:
- Apple does not allow updating native code on the fly. Interestingly enough, they do allow this with non-native code like JavaScript: and this is why solutions where business logic is written using JavaScript, bug fixes are pushed to the client are gaining popularity. Solutions include React Native or Cordova with services like Codepush are gaining strong traction. At Uber, we've built a homegrown solution among the same lines, as several other companies have done so.
- It takes hours to days to release a new app version on the store. This is more pronounced for iOS, where a manual app review needs to take place. Historically, every review had the possibility of rejection. As of June 2020, Apple has changed guidelines, so bug fixes are no longer be delayed over guideline violations, except for legal issues.
- Users take days to update to the latest version after a new version is published to the app store. This lag is true even for users with automated updates turned on.
- You can not assume that all users will get this updated version, ever. Some users might have automated updates disabled. Even when they update, they might skip several versions.
Chuck Rossi, part of release engineering at Facebook, summarizes what it's like to release for mobile on a Software Engineering Daily podcast episode like this:
It was the most terrifying thing to take 10,000 diffs, package it into effectively a bullet, fire that bullet at the horizon and that bullet, once it leaves the barrel, it's gone. I cannot get it back, and it flies flat and true with no friction and no gravity till the heat death of the universe. It's gone. I can't fix it.
This means that all previous versions of your app need to be supported indefinitely - at least in theory, you should do this. The only exception is if you put homegrown controls in place and build a force update mechanism to limit the past versions to support. Android supports in-app updates through the Play Core library. iOS doesn't have similar native support. We'll cover force updates in the "Force upgrading" section in Part 3 of the series.
Assuming that you have an app with millions of users, what steps can you take to minimize bugs shipped to users or regressions happening in old versions?
- Do thorough testing at all levels. Automated testing, manual testing, and consider beta testing with easy feedback loops. A common approach at many companies is releasing the beta app to company employees and beta users and having it "bake" for a week, collecting feedback on any issues.
- Have a feature flagging system in place, so you can revert bugs on the fly. Still, feature flags add further pain points - we'll discuss these points in the "Feature flag hell" section in Part 3 of the series.
- Consider gradual rollouts, with monitoring to ensure things work as expected. We'll cover monitoring in more detail in Part 3 of the series.
- Force upgrading is a robust solution - but you'll need to put one in place, and some customers might churn as a result.
3. The Long Tail of Old App Versions
Old versions of the app will stay around for a long time - up to a number of years. This timeframe is only shorter if you're one of the few teams that put strict force app upgrade policies in place. Apps that have a rolling window of force upgrades include Whatsapp and Messenger. Several others use force upgrades frequently, like banking apps Monzo or American Express.
While most users will update to new app versions in a matter of days, there will be a long tail of users being on several versions behind. Some users disable automatic updates on purpose, but many who don't update are blocked because of old phones or OSes. At the same time, old app versions are unlikely to be regularly tested by the mobile team: it's a lot of effort, with little payoff.
Even a non-breaking backend change can break an older version of the app - such as changing the content of a specific response. A few practices you can do to avoid this breakage:
- Build sturdy network response handling and parsing, using dedicated tooling that solves for these problems. Prefer strongly typed, generated contracts between client and backend like Thrift, GraphQL, or other solutions with code generation over REST interfaces that you need to validate manually - which is bound to break when someone forgets to update the parsing logic on mobile.
- Plan well in advance for breaking backend changes. Have an open communications channel with the backend team. Have a way to test old app versions. Consider building new endpoints and not retiring old ones until a forced upgrade moves all current app users off the old endpoint.
- Version your backend endpoints and create new versions to accommodate breaking changes. Note that in case of using GraphQL, GraphQL has a strong stance against versioning. When making breaking changes, you'd usually create a new endpoint and mark the existing one as deprecated.
- Take care when deprecating endpoints on the backend: monitor the traffic, and have a migration plan on how to channel requests, if needed.
- Track usage stats on an app version level. What percentage of users is lagging three or more versions behind? Once you have this data, it's easier to decide how much effort to dedicate towards ensuring the experience works well on older versions.
- Put client-side monitoring and alerting in place. These alerts might be channeled to a dedicated mobile oncall, or just the normal oncall. We'll dive into monitoring and alerting in more detail in Part 3 of the series.
- Consider doing upgrade testing, at least for major updates. Upgrade testing is expensive, hard to automate, and there might be several permutations to try. Teams rarely do it because of this overhead.
4. Deeplinks
Deeplinking - providing a web or device link that opens a part of the app - becomes a surprisingly tricky problem on both mobile platforms. Both iOS and Android offer APIs to deal with this, but without any opinionated native frameworks or recommended approaches. As Alberto De Bortoli puts it in his excellent article deeplinking at scale, on iOS:
Deep linking is one of the most underestimated problems to solve on mobile.
There are a few things that make deeplinking challenging:
- Backward compatibility: ensuring that existing deeplinks keep working in older versions of the app - even when significant navigation or logic changes happened.
- State problems when deeplinking to a running app with existing state. Say you have an app open and are on a detail page. You tap on a deeplink in your mail app that points to another detail page. What should happen? Would the new detail page be added to the navigation stack, preserving your current state? Or should the state be reset? The solution that results in the least amount of non-deterministic behavior is to reset the app's state fully when receiving a deeplink. However, there might be flows that you don't want to break: plan carefully.
- iOS and Android deeplink implementation differences. Deeplink implementations are different for iOS (Universal links and URL schemes) and for Android (based on intents). There are third-party deeplink providers that provide abstractions to work with a single interface: Branch and Firebase Dynamic Links are such providers, among others.
- Lack of upfront planning. Deeplinks are often an afterthought after having shipped multiple versions of the app. However, unlike on the web where adding links/deeplinks are more straightforward, retrofitting a deeplinking strategy can be a real engineering challenge. Deeplinks are connected to state management and the navigation architecture (we'll discuss this area in Part 2 of the series).
The biggest problem with deeplinks is how neither iOS nor Android provides a much-needed opinionated approach on how to architect - and test - deeplinks. As the number of deeplinks grows, the complexity of keeping these deeplinks working as intended snowballs. You'll have to plan well ahead in building a sensible - and scalable - deeplink implementation.
5. Push and Background Notifications
App push notifications are a frequently used notification, communication, and marketing tool. The business loves to use push notifications, and as a developer, you'll be asked to support this communications method, sooner or later. However, push notifications bring a set of new challenges you'll need to tackle.
Setting up and operating push notifications is complex. Both for Android and iOS, your app needs to obtain a token from a server (FCM on Android, APNS on iOS), then store this token on the backend. There are many steps to take to get push notifications working: see this comprehensive tutorial for iOS and one for Android.
Sending push notifications has to happen from the backend: you'll need to work with the backend team on the type of notifications they want to send and their triggers. Your backend counterparts will have to become familiar with the mobile push notification infrastructure and capabilities to make the most out of this channel.
Users can opt out of push notifications or not opt in to start with. On iOS and Android, you have different ways - and limitations - in detecting when this is the case. Push notifications are usually a "nice to have" for many applications, exactly because you cannot guarantee that each user will opt into them - or that their device will be online to receive them.
Using push notifications together with emails and text messages is a popular strategy for marketing activities. If your app is used for marketing purposes, you'll almost certainly not implement push notifications from scratch. You'll use a third-party customer engagement service like Twillio, Airship, Braze, OneSignal, or similar.
Push notifications come with the same challenges as deeplinks for the action the notification performs. A push notification is a glorified deeplink: a message with an action that links into the app. Thinking about backward compatibility, state problems, and planning ahead all apply for push notifications as well.
Testing push notifications is another pain point. You can, of course, test this manually. However, for automated testing, you need to write end-to-end UI tests: expensive tests to create and to maintain. See this tutorial on how to do this for iOS.
Background notifications are a special type of push message that is not visible for the user, but goes directly to your app. These kinds of notifications are useful to sync backend updates to the client. These notifications are called data messages on Android and background notifications on iOS - see an example for iOS usage.
The concept of background notifications is handy for realtime and multi-device scenarios. If your app is in this area, you might decide to implement a cross-platform solution across iOS and Android, and instead of the mobile app polling the server, the server sends data through background push notifications to the client. When rewriting Uber's Rider app in 2016, a major shift in our approach was exactly this: moving from poll to push, with an in-house push messaging service.
Background notifications can simplify the architecture and the business logic, but they introduce message deliverability issues, message order problems, and you'll need to combine this approach with local data caching for offline scenarios.
6. App Crashes
An app crashing is one of the most noticeable bug in any mobile app - and often ones with high business impact. Users might not complete a key flow, and they might grow frustrated and churn or leave poor reviews.
Crashes are not a mobile-only concern: they are a major focus area on the backend, where monitoring uncaught exceptions or 5XX status codes is common practice. On the web, due to its nature - single-threaded execution within a sandbox - crashes are rarer than with mobile apps.
The first rule of crashes is you need to track when they happen and have sufficient debug information. Once you track crashes, you'll want to report on what percentage of sessions end up crashing: and reduce this number as much as you can. At Uber, we tracked the crash rates from the early days, working continuously to reduce the rate of crashed sessions.
You can choose to build your own implementation of crash reporting or use an off-the-shelf solution. Coming up to 2021, most teams choose one of the many crash reporting solutions such as Crashlytics, Bugsnag, Sentry, and others.
On iOS, crash reports are generated on the device with every crash that you can use to map these logs to your code. Apple provides ways for developers to collect crash logs from users who opted to share this information via TestFlight or the App Store. This approach works well enough for smaller apps. On Android, Google Play also lets developers view crash stack traces through Android Vitals in the Play Console. As with Apple, only users who have opted in to send bug reports to developers will have these crashes logged in this portal.
Third-party or custom-built crash reporting solutions offer a few advantages on top of what the App Store and Google Play have to offer. The advantages are plenty, and most mid-sized and above apps go with either a third party or build a solution with the below benefits:
- More diagnostic information. You'll often want to log additional information in your app on events that might lead up to a crash.
- Rich reporting. Third-party solutions usually offer grouping of reports and comparing iOS and Android crash rates.
- Monitoring and alerting capabilities. You can set up to get alerts when a new type of crash appears or when certain crashes spike.
- Integrations with the rest of the development stack. You'll often want to connect new crashes with your ticketing system or reference them in pull requests.
At Uber, we used third-party crash reporting from the early days. However, an in-house solution was built later. A shortcoming of many third-party crash reporting solutions is how they only collect health information on crashes and non-fatal errors, but not on app-not-responding (ANR) and memory problems. Organizations with many apps might also find the reporting not rich enough and might want to build their own reporting to compare health statuses across many apps. Integrating better with in-house project management and coding tools could also be a reason to go custom.
Reproducibility and debuggability of crashes are another pain point that impacts mobile more than backend or web teams. Especially in the Android world, users have a variety of devices that run a wide range of OS versions with a variety of app versions. If a crash can be reproduced on a simulator or on any device: you have no excuse not to fix the problem. But what if the crash only happens on specific devices?
Put a prioritization framework in place to define thresholds, above which you'll spend time investigating and fixing crashes. This threshold will be different based on the nature of the crash, the customer lifetime value, and other business considerations. You need to compare the cost of investigation and fixing compared to the upside of the fix, and the opportunity cost lost in an engineer spending time on something else, like building revenue-generating functionality.
7. Offline Support
Though offline support is becoming more of a feature with rich web applications, it has always been a core use case with native mobile apps. People expect apps to stay usable, even connectivity drops. They certainly expect state not to get lost when the signal drops or gets weaker.
Proper offline mode support adds a lot of complexity and interesting edge cases to an app. State needs to be persisted, locally and when connection recovers, it needs to be synchronized back. You need to account for race conditions when a user uses the app on multiple devices - some online, one offline. You should take additional care with app updates that modify the locally stored data, migrating the "old" data to the "new" format - we'll cover this challenge in Part 3 of the series.
Decide what features should work offline and which ones should not. Many teams miss this simple step that makes the planning of the offline functionality easier and avoids scope creep. I suggest starting with the key parts of the application and expand this scope slowly. Get real-world feedback that the "main" offline mode works as expected. Can you leverage your approach in other parts of the app?
Decide how to handle offline edge cases. What do you want to do with extremely slow connections: where the phone is still online, but the data connection is overly slow? A robust solution is to treat this as offline and perhaps notify the user of this fact. What about timeouts? Will you retry?

Retries can be a tricky edge case. Say you have a connection that has not responded for some time - a soft timeout - and you retry another request. You might see race conditions or data issues if the first request returns, then the second request does so as well.
Synchronization of device and backend data is another common yet surprisingly challenging problem. This problem multiplied with multiple devices. You need to choose a conflict resolution protocol that works well enough for multiple parallel offline edits and is robust enough to handle connectivity dropping midway.
With poor connectivity, the network request can sometimes time out. Sensible retry strategies or moving over to offline mode could be helpful. Both solutions come with plenty of tradeoffs to think about.
Retry strategies come with edge cases you need to think about. Before retrying, how can you be sure that the network is not down? How do you handle users frantically retrying - and possibly creating multiple parallel requests? Will the app allow the same request to be made while the previous one has not completed? With a switch to offline mode, how can the app tell when the network has reliably recovered? How can the app differentiate between the backend service not responding versus the network being slow? What about resource efficiency - should you look into using HTTP conditional requests with retries utilizing ETags or if-match headers?
Much of the above situations can be solved relatively simply when using reactive libraries to handle network connections - the likes of RxSwift, Apple's Combine, or RxJava. An edge case goes beyond the client side, which does get tricky: retries that should not be blindly retried.
Requests that should not be retried come with a separate set of problems. For example, you might not want to retry a payment request while it's in progress. But what if it comes back as failed? You might think it's safe to do so. However, what if the request timed out, but the server made the payment? You'll double charge the user.
As a consumer of backend endpoints, you should push all retries on API endpoints to be safe by having these endpoints be idempotent. With idempotent endpoints, you'll have to obtain and send over idempotency keys and keep track of an additional state. You'll also have to worry about edge cases like the app crashing and restarting and the idempotency key not being persisted. Implementing retries safely adds a lot of mental overhead for teams. You'll have to work closely with the backend team to map the use cases to design for.
As with state management, the key to a maintainable offline mode and weak connection support is simplicity. Use immutable states, straightforward sync strategies, and simple strategies to handle slow connections. Do plenty of testing with the right tools such as the Network Link Conditioner for iOS or the networkSpeed capability on Android emulators.
8. Accessibility
Accessibility is a big deal for popular applications, a few reasons:
- If you have a large number of users, many of them will have various accessibility needs, finding it difficult - or impossible - to interact with your app without adequate support for these.
- If the app is not accessible, there is an inherent legal risk for the app's publisher: several accessibility lawsuits targeting native mobile apps are already happening in the US.
Accessibility is not only a "nice" thing to do: your app quality increases as you make it more accessible. This thought comes from Victoria Gonda, who has collected excellent iOS and Android accessibility resources.
Before you start, you'll need to confirm the level of depth you'll go into implementing WCAG 2.1 mobile definitions. Ensuring the app is workable for sighted people over VoiceOver (iOS) / TalkBack (Android) and making sure colors/key elements are contrastful enough are typical baseline expectations. Depending on your application type, you might need to consider hearing people or users with other accessibility needs.
Accessibility goes deeper than ensuring sighted people can use the app. Allowing people's accessibility preferences to work with the app, such as supporting the user's font size of choice - Dynamic Type support on iOS and using scale-independent pixels as measurement on Android are both practices you should follow. You'll also need to take device fragmentation into account. For example, in the Android world, the OnePlus model is known to have a different font size to the rest of the ecosystem.
Implementing accessibility from the start is a surprisingly low effort on iOS and a sensible one for Android. Both platforms have thought deeply about accessibility needs and make it relatively painless to add accessibility features.
Retrofitting accessibility is where this problem can be time-consuming. Making accessibility part of the design process is a better way to go about things - this is why it's a good idea to make accessibility part of your planning/RFC process. Thinking in VoiceOver frames at a page level (iOS) and following accessibility best practices from the start are a good investment.
Testing accessibility is something that needs planning. There are a few levels of accessibility testing you can - and should add:
- Automate the parts of accessibility checks that can be automated - like checking for accessibility labels on screen elements. On iOS, you can also have VoiceOver content displayed as text and potentially automate these checks as well.
- Manually test accessibility features: do this at least semi-regularly, as part of the release process.
- Recruit accessible users in your beta program to get feedback directly from them. This is more feasible for larger companies - however, the payoff of having these users interact with the engineering team can be a major win.
- Turn on accessibility features during development where it's sensible to do so. This way, you can inspect these working and get more empathy on how people who rely on these would use them.
9. CI/CD & The Build Train
CI/CD for simple backend services and small web applications is straightforward. Yet, even for simple mobile applications, it is less so: mostly because of the app store's manual submission step. On Android, you can automate this process, as you can with enterprise iOS apps: just not for App Store releases.

iOS and Android platforms are different: each requires their own build systems and separate pipelines. Companies who end up going with a third-party CI will also struggle to find a simple-to-use solution, and in the end, will probably choose Bitrise. Bitrise is the only mature service on the market that started with iOS and Android CI as their core offering. All other CI services try to "lump in mobile" on top of the backend CI offerings, and it's just more painful.
Bitrise is CI/CD built for mobile - by mobile engineers. From pull request, to app store submission and beyond, Bitrise automates, monitors and improves your app development workflows. Teams who use Bitrise build better quality apps, deliver them faster, with developers who are happy.
Bitrise supports native Android,iOS, React Native, Flutter and builds with other popular mobile frameworks. Need support for a specific development step like testing, code signing, or notifying when a build has issues? With an open source library of hundreds of integrations you’ll probably find what you need: or be able to build it quickly.
More than 100.000 developers and thousands of organizations trust Bitrise. Try it for free and build better apps, faster.
When owning your own infrastructure and having some dedicated staffing for builds, solutions like Buildkite can give more control and a better experience than third-parties. A few mobile leads at medium and large teams shared how they are happier with keeping builds in-house, despite the higher cost.
You'll find yourself using popular build tools to automate various build steps, such as uploading to the app store. For iOS, this will likely be Fastlane, and for Android builds running on Jenkins, it could be a Jenkinsfile or similar.
Be vary of maintaining your homegrown CI system if you won't have dedicated people bandwidth to support this. I've seen startups repeatedly set up a Jenkins CI, get it running, just to realize months later that someone needed to keep dealing with infrastructure issues and the growing pile of Mac Minis. I suggest to either offload the build infra to a vendor or have a dedicated team owning mobile build infrastructure. At Uber, we had a dedicated mobile infra team who owned things like the iOS and Android monorepo or keeping master green at scale.
The build train is the next step after you have a CI in place. A build train is a way to track the status of each of your weekly or bi-weekly releases. Once a release cut is made for a "release candidate" for the app store, a series of validation steps need to happen: some of these automatic, some of them being manual. These steps can include running all automated and manual tests, localizing new resources, dogfooding, and others.
Once the release candidate is validated, it is uploaded to the app store and waits on approval. After approval, you might roll out with a staged release - a phased rollout on iOS and staged rollouts on Android.
Your build train would visualize the status of all of the above: which commit was the build candidate cut, where the validation process is, and what the staged rollout status is. The release manager might manually track the build trains. Companies with complicated release steps and mobile infra teams tend to build their custom solution - we did this at Uber.
10. Device and OS Fragmentation
Device model and OS fragmentation is an everyday problem on both platforms. Device fragmentation and weird, hardware-related bugs have always been familiar pain points on Android. OS fragmentation is less of an issue on iOS, while it keeps getting worse on Android.
Keeping on top of new OS releases and the accompanying API changes require a focus from mobile engineers. Both iOS and Android keep innovating: features and APIs keep being added, changed, and deprecated. It's not just big changes SwiftUI or Dark Mode on iOS13, biometric authentication APIs on iOS 8 (2014), and on Android 10 (2019). There are several smaller APIs, like credit card autofill on Android Oreo - that exist on one platform, with no equivalent on the other. In all honesty, learning about the new APIs on WWDC or Google I/O, then adding them to the app is the fun part.
Making sure the app keeps working without issues on older OS and devices is more of a challenge. You'll typically need to either set up an in-house device lab or use a third-party testing service to ensure that the app works correctly on all major models.

Android has far more quirks when it comes to edge cases and crashes that are specific to certain devices. For example, Samsung devices are well-known for strange crashes related to the Samsung Android customization - not to mention special layout considerations for the Galaxy Fold. Amazon's Fire OS is another problematic device to support, thanks to the forked Android version these devices run on. Crash reports, user bug reports, and large-scale manual testing are ways to stay on top of new issues and regressions. All of these will be far more time consuming and expensive than most people expect.
Android has one more fragmentation issue: Android forks that do not run on Google's ecosystem. Apps built for Fire OS or future Huawei devices won't have access to Google Play Services. This means functionality like Firebase notifications won't work. For businesses that want to support these devices, using alternative approaches will mean additional time spent building, testing, and maintaining.
Deciding how and when to stop supporting old OS versions is a process your mobile team should put in early on. The cost of supporting old iOS and Android versions are high: and the payoff can be low. The business will naturally push to support as many devices as possible. The team needs to quantify what this support adds up to. When revenue or profits from the old version is less than the cost to maintain, the pragmatic solution is to drop support for old OSes.
While there might be legal requirements in certain industries to support old OSes, the smaller windows you support, the faster you'll be able to move. At the end of 2020, it's common for Android teams to support from version 24 and up (Nougat) - but rarely going back to before v21 (Lollipop). On iOS, thanks to more rapid OS adoption, many businesses for versions beyond the last two or three ones, soon after a new OS release.
Next Part and Credits
Interested in reading the next partd? You can do so in the ebook Building Mobile Apps at Scale.
Thank you to the more than 15 mobile engineers and managers with deep expertise, who have contributed to and reviewed this series. Special thanks to their insights and feedback. If you're on Twitter, you should follow them:
- Abhijith Krishnappa (Halodoc)
- Andrea Antonioni (Just Eat)
- Artem Chubaryan (Square)
- Barisere Jonathan
- Corentin Kerisit (Zenly)
- Franz Busch (Sixt)
- Guillermo Orellana (Monzo, Skyscanner, Badoo)
- Injy Zarif (Convoy, Microsoft)
- Jake Lee
- Javi Pulido (Plain Concepts)
- Jared Sheehan (Capital One)
- Julian Harty
- Matija Grcic
- Michael Bailey (GDE, American Express)
- Michael Sena (Amazon)
- Patrick Zearfoss
- Robin van Dijke (Uber, Apple)
- Rui Peres (Sphere)
- Tuğkan Kibar
- Will Larson
Updates to this article:
- 16 Dec 2020: corrected Android supporting background notifications - thank you, Michael Bailey for the feedback!
- 21 Dec 2020: updating dates to the follow-up articles. I've decided to make this a "proper" book
- April 2021: published the book Building Mobile Apps at Scale!
- 8 Sep 2024: updated the article to link to the book for the other 29 challenges
Subscribe to my weekly newsletter to get articles like this in your inbox. It's a pretty good read - and the #1 software engineering newsletter on Substack.