For the past few years, I've been building and operating a large distributed system: the payments system at Uber. I've learned a lot about distributed architecture concepts during this time and seen first-hand how high-load and high-availability systems are challenging not just to build, but to operate as well. Building the system itself is a fun job. Planning how the system will handle 10x/100x traffic increase, ensuring data is durable, regardless of hardware failures is intellectually rewarding. However, operating a large, distributed system has been an eye-opening experience for myself.
The larger a system, the more Murphy's law of "what can go wrong, will go wrong" applies. This is especially true with frequent deploys, lots of developers deploying code, multiple data centers involved, and the system being used globally by a large number of users. The past few years, I've experienced a variety of system failures, many of which surprised me. These went from predictable things like hardware faults or innocent bugs making it into production, all the way to network cables connecting data centers being cut or multiple cascading failures occurring at the same time. I've gone through dozens of outages, where parts of the system were not working correctly, resulting in large business impact.
This post is the collection of the practices I've found useful to reliably operate a large system at Uber, while working here. My experience is not unique - people working on similar sized systems go through a similar journey. I've talked with engineers at Google, Facebook, and Netflix, who shared similar experiences and solutions. Many of the ideas and processes listed here should apply to systems of similar scale, regardless of running on own data centers (like Uber mostly does) or on the cloud (where Uber sometimes scales to). However, the practices might be an overkill for smaller or less mission-critical systems.
There's much ground to cover - I'll go through the following topics:
- Monitoring
- Oncall, Anomaly Detection & Alerting
- Outages & Incident Management Processes
- Postmortems, Incident Reviews & a Culture of Ongoing Improvements
- Failover Drills, Capacity Planning & Blackbox Testing
- SLOs, SLAs & Reporting on Them
- SRE as an Independent Team
- Reliability as an Ongoing Investment
- Further Recommended Reading
Monitoring
To know if a system is healthy, we need to answer the question "Is my system working correctly"? To do so, it is vital to collect data on critical parts of the system. With distributed systems that run multiple services, on multiple machines and data centers, it can be difficult to decide what key things really need to be monitored.
Infrastructure health monitoring. If one or more machines/virtual machines are overloaded, parts of the distributed system can degrade. The health stats for machines a service operates on - their CPU utilization, memory usage - are basics that are worth monitoring. There are platforms that take care of this monitoring and auto-scaling instances out of the box. At Uber, we have a great core infrastructure team providing infra level monitoring and alerting out of the box. Regardless of how this implemented, being aware when things are in the red for instances or the infrastructure of the service is must-have information.
Service health monitoring: traffic, errors, latency. Answering the question "is this backend service healthy?" is a pretty common one. Observing things like how much traffic is hitting the endpoint, the error rate, and endpoint latency all provide valuable information on service health. I prefer to have dashboards on all of these. When building a new service, by using the right HTTP response mappings and monitoring the relevant codes can tell a lot about the system. So by ensuring 4XX mappings are returned on client errors, and 5xx codes for server errors, this kind of monitoring is easy to build and easy to interpret.
Monitoring latency deserves one more thought. For production services, the goal is for most end users to have a good experience. Turns out, measuring the average latency is not a great metric to do so because this average can hide a small percentage of high latency requests. Measuring the p95, the p99 or p999 - latency experienced by the 95th, 99th or 99.9th percentile of requests - is a lot better metric. These numbers help answer questions like "How fast will the request be for 99% of people?" (p99) or "At least how slow is the request for one in 1,000 people?" (p999) . For those more interested in this topic, this latencies primer article is good further read.
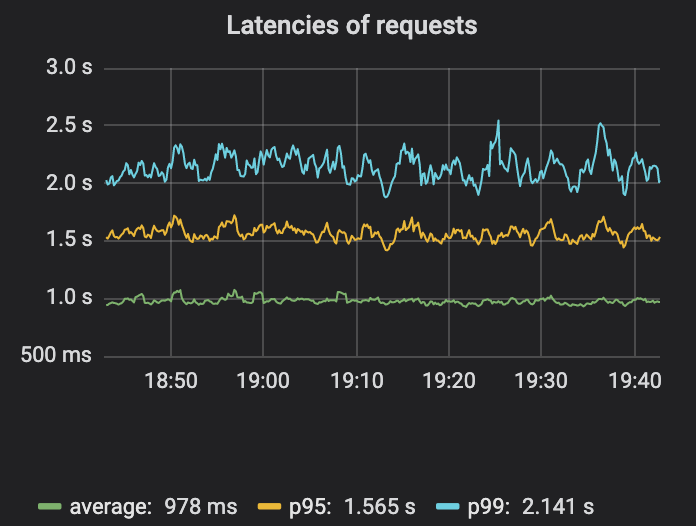
There is a lot more depth around monitoring and observability. Two resources worth reading more are Google's SRE book and the section on the four golden signals of distributed systems monitoring. They suggest if you can only measure four metrics of your user-facing system, focus on traffic, errors, latency, and saturation. The short read is the Distributed Systems Observability e-book from Cindy Sridharan, which touches on other useful tools like event logs, metrics and tracing best practices.
Business metrics monitoring. While monitoring services tells us a lot about how correctly the service seems to work, it tells nothing about whether it works as intended, allowing for "business as usual." In the case of the payments system, a key question is, "can people take trips using a specific payment method?". Identifying business events that the service enables and monitoring these business events is one of the most important monitoring steps.
Business metrics monitoring was something my team built after having been bruised by outages that we had no way to detect otherwise. All our services looked like they were operating normally, yet key functionality was down across services. This kind of monitoring was quite bespoke to our organization and domain. As such, we've had to put a lot of thought and effort into customizing this type of monitoring for ourselves, building on the observability tech stack at Uber.
Oncall, Anomaly Detection, and Alerting
Monitoring is a great tool for people to inspect the current state of the system. But it's really just a stepping stone to automatically detect when things go wrong and raise alerts that people can take action on.
Oncall itself is a broad topic - Increment magazine did a great job covering many aspects in its On-Call issue. I strongly prefer thinking of oncall as a follow-up to the "you build it, you own it" mindset. Teams who build services own them, owning the oncall as well. My team owned oncall for the payments services that we built. So whenever an alert fires, the oncall engineer would respond and look into the details. But how do we get from monitoring to alerts?
Detecting anomalies from the monitoring data is a tough challenge and an area where machine learning can shine. There are plenty of third-party services that offer anomaly detection. Again lucky for my team, we had an in-house machine learning team to work with, who tailored their solutions to Uber use-cases. The NYC-based Observability team wrote a helpful article on how anomaly detection works at Uber. From my team's point of view, we push our monitoring data to this team's pipeline and get alerts with the respective confidence levels. Then we decide if we should page an engineer or not.
When to fire an alert is an interesting question. Too few alerts can mean missing impactful outages. Too many can cause sleepless nights and burn people out. Tracking and categorizing alerts and measuring signal-to-noise is essential in tweaking the alerting system. Going through alerts and tagging whether they were actionable or not, then taking steps to reduce non-actionable alerts is a good step towards having sustainable on-call rotations in place.
The Uber developer tooling team based in Vilnius builds neat on-call tooling that we use to annotate alerts and visualize the oncall shifts. Our the team holds a weekly review of the last oncall shift, analyzing pain points and spending time to improve the oncall experience, week after week.
Outages & Incident Management Processes
Imagine this: you're the engineer oncall for the week. A pager alert wakes you up the middle of the night. You investigate if there's a production outage happening. Uh oh. Seems like part of the system is down. Now what? Monitoring and alerting just got very real.
Outages might not be that big of a deal for small systems, where the oncall engineer can understand what is happening and why. They are usually quick to understand and easy to mitigate. For complex systems with multiple (micro)services, lots of engineers pushing code to production, it is challenging enough just to pinpoint where the underlying problem is happening. Having a few standard processes to help with this makes a huge difference.
Runbooks that are attached to alerts, describing simple mitigation steps are the first line of defense. For teams that have good runbooks, it's rarely a problem if the engineer oncall does not know the system in-depth. Runbooks need to be kept up to date, updated, and re-worked with new type of mitigations, as they happen.
Communicating outages across the organization become essential as soon as there are more than a few teams that deploy services. In the environment I work at, thousands of engineers deploy services they work on into production when they see fit, resulting in hundreds of deploys per hour. A seemingly unrelated deployment on one service might impact another one. Here, standardized outage broadcasting and communication channels make a big difference. I've had multiple cases when an alert was unlike anything I've seen before - and realizing that other people in other teams are seeing similarly odd things. Being in a central chat group for outages, we pinpointed the service causing the outage and mitigated the issue quickly. We did this much faster, as a group than any one of us would have done it by ourselves.
Mitigation now, investigation tomorrow. In the middle of an outage, I often got the "adrenalin rush" of wanting to fix what went wrong. Often the root cause was a bad code deploy, with a glaring bug being present in the code change. In the past, I would have jumped to fix the bug, push the fix and close the outage over just rolling back the code change. However, fixing the root cause in the middle of an outage is a terrible idea. There is little to gain and a lot to lose with a forward fix. Because the new fix has to be done quickly, testing has to be done in production. Which is the recipe to introduce a second bug - or a second outage - on top of the existing one. I have seen outages blow up, just like this. Just focus on mitigating first, resisting the urge to fix or investigate the root cause. A proper investigation can wait until the next business day.

Postmortems, Incident Reviews & a Culture of Ongoing Improvements
It is telling of a team how they handle the aftermath of an outage. Do they carry on? Do they do a small investigation? Do they perhaps spend a surprisingly large effort on the follow-up, stopping product work to make system-level fixes?
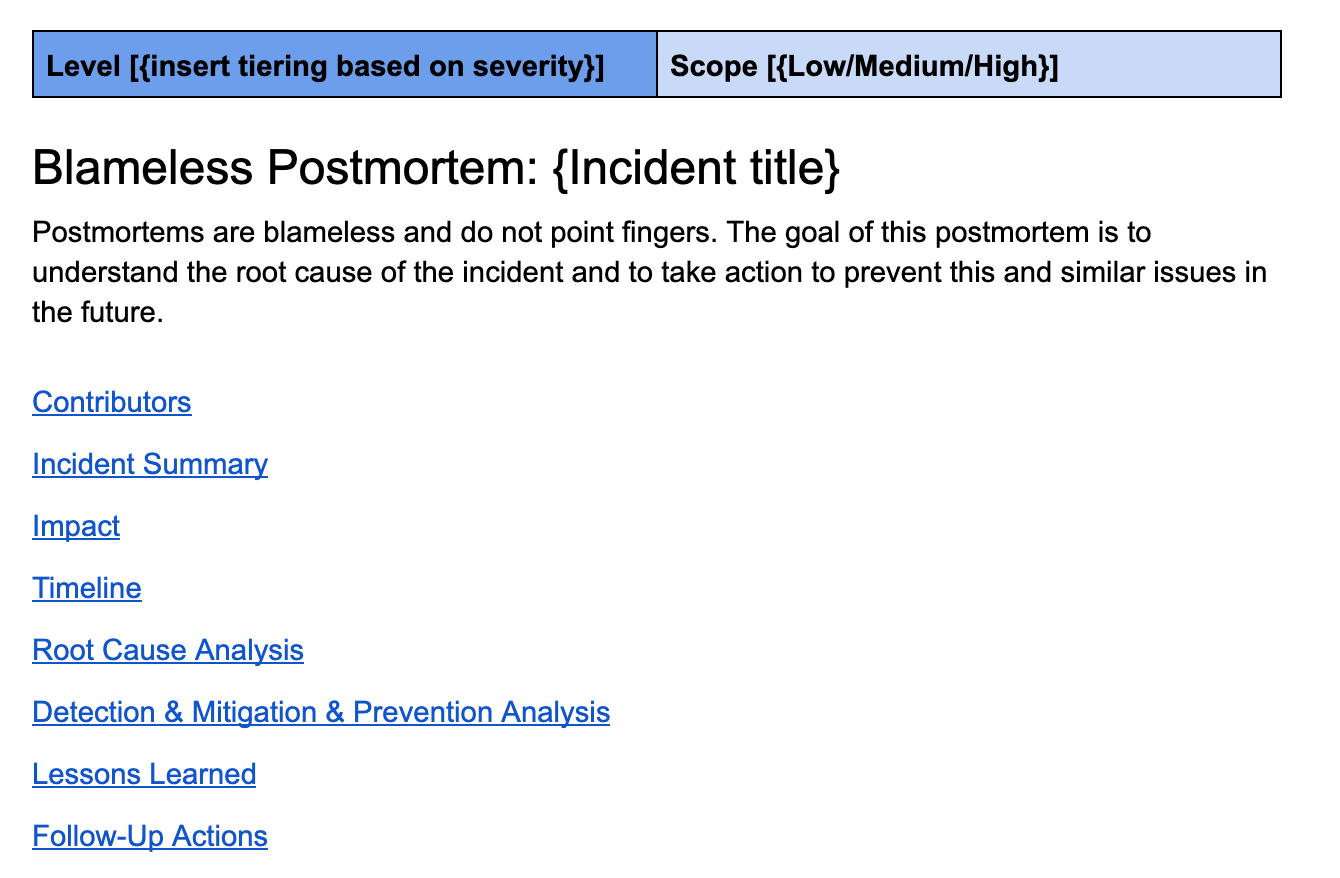
Postmortems done right are a building block for robust systems. A good postmortem is blameless yet thorough. Templates for postmortems at Uber evolved over time across engineering, having sections for the summary of the incident, impact overview, the timeline of events unfolding, a root cause analysis, lessons learned and a list of detailed follow-up items.
Good postmortems dig deep down into the root cause and come up with improvements to make preventing, detecting or mitigating all similar outages a lot faster. When I say dig deep, I mean they won't stop at the root cause being a bad code change with a bug that the code reviewer did not spot. They dig deeper with the "5 Whys" exploration technique, to dig deeper, arriving at a more meaningful conclusion. Take this example:
- Why did the issue happen? --> A bug was committed as part of the code.
- Why did the bug not get caught by someone else? --> The code reviewer did not notice that the code change could cause such an issue.
- Why did we depend on only a code reviewer catching this bug? ---> Because we don't have an automated test for this use case.
- "Why don't we have an automated test for this use case?" --> Because it is difficult to test without test accounts.
- Why don't we have test accounts? --> Because this system does not yet support them
- Conclusion: this issue points to the systemic issue of not having test accounts. Suggesting to add test accounts support to the system. Following this, write automated tests for all future, similar code changes.
Incident reviews are an important accompanying tool for postmortems. While many teams do a thorough job with postmortems, others can benefit from additional input and being challenged on preventative improvements. It's also essential that teams feel accountable and empowered to carry out the system level improvements they propose.
For organizations that are serious about reliability, the most severe incidents get reviewed and challenged by the experienced engineers. Organizational level engineering management should also be present to provide empowerment to go through with the fixes - especially when those are time-consuming and block other work. Robust systems are not built overnight: they are built through continuous iterations. Iterations that come from an organization-wide culture of continuous improvements, following learning from incidents.
Failover Drills, Planned Downtime & Capacity Planning & Blackbox Testing
There are a couple of regular activities that require significant investments but are critical in keeping a large distributed system up and running. These are concepts I came across at Uber for the first time - at previous companies, we did not need to use these as our scale and infrastructure did not prompt us to do so.
A data center failover drill is something I assumed was dull until I observed a a few of them. I was initially thinking, designing robust distributed systems is precisely about being resilient to data centers going down. Why test it regularly, if it should theoretically just work? The answer has to do with scale and testing whether services can efficiently handle a sudden increase in traffic in a new data center.
The most common failure scenario I have observed is services not having enough resources in a new data center to handle global traffic, in case of a failover. Imagine ServiceA and ServiceB running from two data centers each. Let's assume that utilization of the resources is at 60% - with tens or hundreds of VMs running in each DC - and alerts are set to trigger at 70%. Now let's do a failover, directing all traffic from DataCenterA to DataCenterB. DataCenterB is suddenly unable to cope with the load, without provisioning new machines. Provisioning could take long enough time that requests get piled up and start dropping. This blocking could start to impact other services, causing a cascading failure on other systems, that are not even part of this failover.
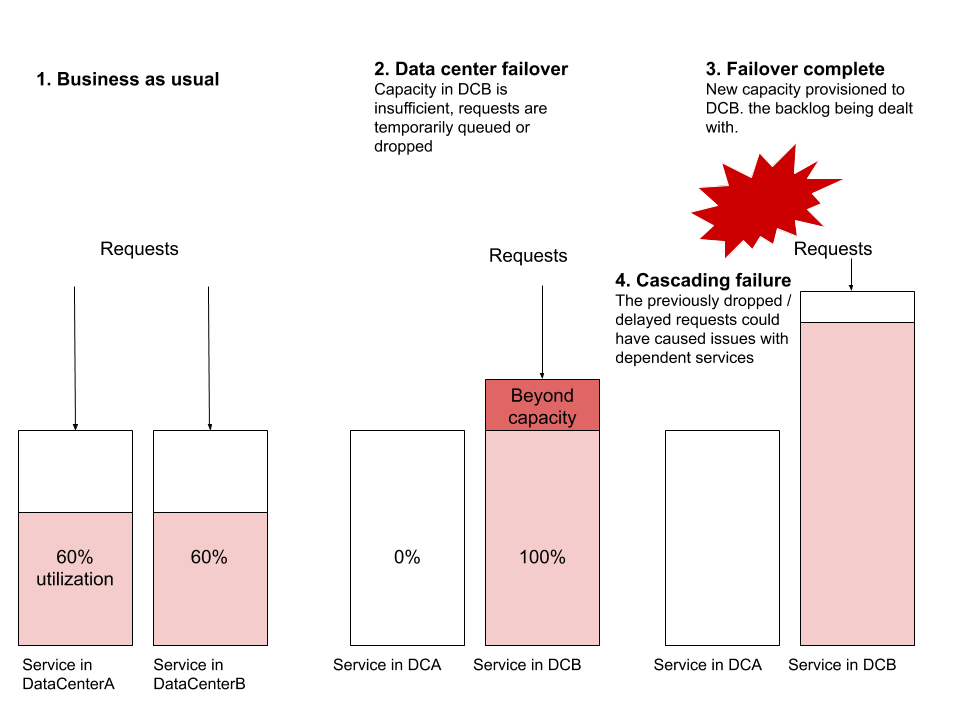
Other common failure scenarios involve routing level issues, network capacity problems, or back pressure pain points. Data center failovers are drills that any reliable distributed system should be able to perform without any user impact. I am emphasizing should - this drill is one of the most useful exercises to test the reliability of a web of distributed systems.
Planned service downtime exercises are an excellent way to test the resiliency of the overall system. These are also a great way to discover hidden dependencies or inappropriate/unexpected usages of a specific system. While this exercise can be done relatively easily with services that are client facing and have few known dependencies, it is less straightforward to do with critical systems that require high uptime and or with ones that many other systems depend on. But what will happen when this critical system will be unavailable, someday? It is better to validate the answer with a controlled drill, all teams being aware and ready, over an unexpected outage.
Black-box testing is a way to measure the correctness of a system as close to the conditions as an end user would see it. This type of testing is similar to end-to-end testing. Except that for most products, having proper black-box tests warrant their own investment. Key user flows, and the most common, user-facing test scenarios are good ones to make "black box testable": doing this in a way that they can be triggered any time, to check if the systems work.
Taking Uber as an example, an obvious black-box test is checking if the rider-driver flow works at a city level. That is, can a rider in a specific city request an Uber, being matched with driver partners and get a ride? Once this scenario is automated, this test can be regularly run, simulating different cities. Having robust black-box testing systems makes it easier to verify that the system - or parts of the system - work correctly. It also helps a lot with failover drills: the quickest way to get feedback on the failover is to run the black-box tests.
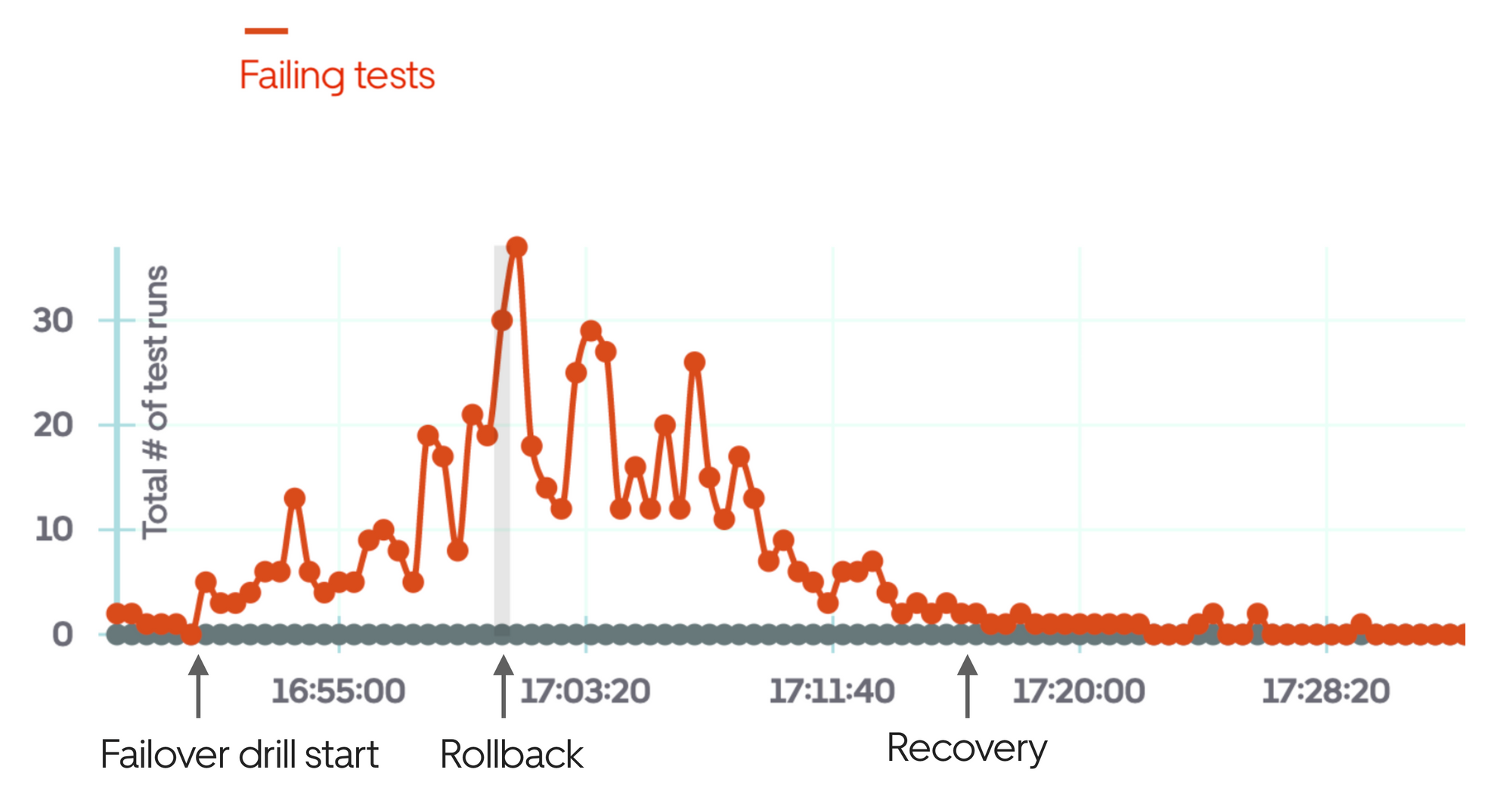
Capacity planning becomes equally important for large distributed systems. By large, I mean the cost of compute and storage being in the tens- or hundreds of thousands dollars per month. At this scale, having a fixed number of deployments might be cheaper over using self-scaling cloud solutions. At the very least, fixed deployments should handle the "business as usual" traffic, with automatic scaling happening for peak loads. But what is the minimum number of instances that should be running for the next month? The next three months? The next year?
Forecasting the future traffic pattern for systems that are mature and have good historical data is not difficult. Yet it is important both for budgeting, for choosing vendors or for locking in discounts with cloud providers. If your service has a large bill and you've not thought of capacity planning, you are missing out on an easy way to reduce and control cost.
SLOs, SLAs & Reporting on Them
SL0 stands for Service Level Objective - a numerical target for system availability. For each independent service, defining service-level SLOs like targets for capacity, latency, accuracy, and availability are good practices. These SLOs can then serve as triggers for alerting. An example service-level SLO could look like this:
| SLO Metric | Subcategory | Value for Service |
|---|---|---|
| Capacity | Minumum throughput | 500 req/sec |
| Maximum expected throughput | 2,500 req/sec | |
| Latency | Expected median response time | 50-90ms |
| Expected p99 response time | 500-800ms | |
| Accuracy | Maximum error rate | 0.5% |
| Availability | Guaranteed uptime | 99.9% |
Business-level SLOs or functional SLOs are an abstraction above the services. They'll cover user or business-facing metrics. For example, a business-level SLO could be this: expecting 99.99% of email receipts to be sent within 1 minute of the trip completed. This SLO might map to service-level SLOs (e.g. latencies of payment and email receipt systems), or they might need to be measured differently.
SLA - Service Level Agreement - is a broader agreement between a service provider and a service consumer. Usually, multiple SLOs make up an SLA. For example, the payments system being 99.99% available could be an SLA, that breaks down to specific SLOs for each supporting system.
After defining the SLOs, the next step is to measure these and report on them. Automating monitoring and reporting on SLAs and SLOs is often a complex project, one that is tempting to de-prioritize for both the engineering team and the business. The engineering team won't be as interested, they already have various levels of monitoring that detect outages realtime. The business, on the other hand, would rather prioritize delivering functionality over investing in a complex project that doesn't have immediate business impact.
Which brings us to the next topic: organizations that are operating large distributed systems sooner or later need to invest dedicated staffing for the reliability of these systems. Let's talk about the Site Reliability Engineering team.
SRE as an Independent Team
Site Reliability Engineering originated from Google from around 2003 - to more than 1,500 SRE engineers today. As operating a production environment becomes a more complex of a task, with more and more automation required, soon enough, this work becomes a full-time job. It varies when companies recognize that they have engineers working close to full time on production automation: the more critical these systems are and the more failures they have, the earlier this happens.
Fast growing tech companies often put an SRE team in-place early on, who build their own roadmap. At Uber, the SRE team was founded in 2015 with the mission of managing system complexity over time. Other companies might couple starting such a team to when a dedicated infrastructure team is created. When a company grows to reliability work across teams takes up more than a few engineers' time, it's time to put a dedicated team for this in place.
With an SRE team in-place, this team makes the operational aspects of keeping large, distributed systems a lot easier for all engineers. The SRE team likely owns standard monitoring and alerting tools. They probably buy or build oncall tooling and are the goto team for oncall best practices. They might facilitate incident reviews and build systems to make detecting, mitigating, and preventing outages easier. They certainly facilitate failover drills, often drive black-box testing, and are involved with capacity planning. They drive choosing, customizing, or building standard tools to define and measure SLOs and report on them.
Given that companies have different pain areas they look for SRE to solve, SRE organizations are different across companies. The name is often something else as well: it could be called operations, platform engineering, or infrastructure. Google published two must-read books on site reliability that are freely available and is an excellent read to go deeper into SRE.
Reliability as an Ongoing Investment
When building any product, building the first version is just the start. After the v1, new features get added in the iterations to come. If the product is successful and brings in business results, the work just keeps on coming.
Distributed systems have a similar lifecycle, except they need more investment, not just for new features, but to keep up with scaling up. As a system starts to take more load, stores more data, has more engineers work on it, it needs continuous care to keep running smoothly. Many people building distributed systems the first time assume this system to be like a car: once built, it only needing essential maintenance every few months. This comparison could not be further from how systems like these operate.
I like to think of the effort to operate a distributed system being similar to operating a large organization, like a hospital. To make sure a hospital operates well, continuous validation and checks are needed (monitoring, alerting, black-box testing). New staff and equipment need to be onboarded all the time: for hospitals, this is staff like nurses and doctors and equipment like new medical devices; for distributed systems it's onboarding new engineers and new services. As the number of people and the number of services grows, new the old ways of doing things become inefficient: the same way a tiny clinic on the countryside works different to a large hospital in a metropolis. It becomes a full-time job to come up with more efficient ways of doing things, and measuring and reporting on efficiency becomes important. Just like large hospitals have more supporting officer staff, like finance, HR or security; operating larger distributed systems similarly rely on supporting teams like infrastructure and SRE.
For a team to run a reliable distributed system, the organization needs to be investing continuously in the operations of these systems, as well as the platforms that they are built on.
Further Recommended Reading
Though this post is lengthy in its content, it still only touches the surface. To dive deeper into operating distributed systems, I recommend the following resources:
Books
- Google SRE Book - a great and free book from Google. The Monitoring Distributed Systems charter is especially relevant for this post.
- Distributed Systems Observability by Cindy Sridharan, another excellent and free book with great points on monitoring distributed systems.
- Designing Data-Intensive Applications by Dr Martin Kleppmann - the most practical book I have found so far on distributed systems concepts. However, this book does not touch much on the operational aspects discussed in the post.
Online resources
- On-Call issue of the Increment magazine: a series of articles on incident response processes of companies like Amazon, Dropbox, Facebook, Google, and Netflix.
- Learning to Build Distributed Systems - a post by AWS engineer Marc Brooker, answering the question "how do I learn to build big distributed systems"?
See the Russian translation of this article here.
Subscribe to my weekly newsletter to get articles like this in your inbox. It's a pretty good read - and the #1 software engineering newsletter on Substack.